



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Introduction
Security breaches in the cloud occur with significant frequency, and proactive planning is essential. But not every threat can be prevented.
Many assume that a strong preventive security posture makes them immune to incidents, only to be caught off guard when one occurs. It’s better to operate under the assumption that a breach is inevitable and prepare accordingly. As cloud attacks grow faster and more sophisticated and the threat landscape becomes less predictable, security leaders must embrace an “assume breach” mindset to stay ahead.
Incident response in AWS environments is crucial for maintaining the security, availability, and overall health of cloud-based applications and infrastructure. In the dynamic world of cloud infrastructure, recovering from a security incident — and tracing the threat actor that caused it — requires a well-defined and practiced incident response plan. Without a robust incident response capability, organizations risk significant financial losses, reputational damage, legal repercussions, and the compromise of sensitive data.
Thankfully, there is a wide variety of open source tools that can facilitate incident response. In this article, we will show how they can be used, and introduce a new publicly available MCP server to help in your efforts.
AWS Shared Responsibility Model
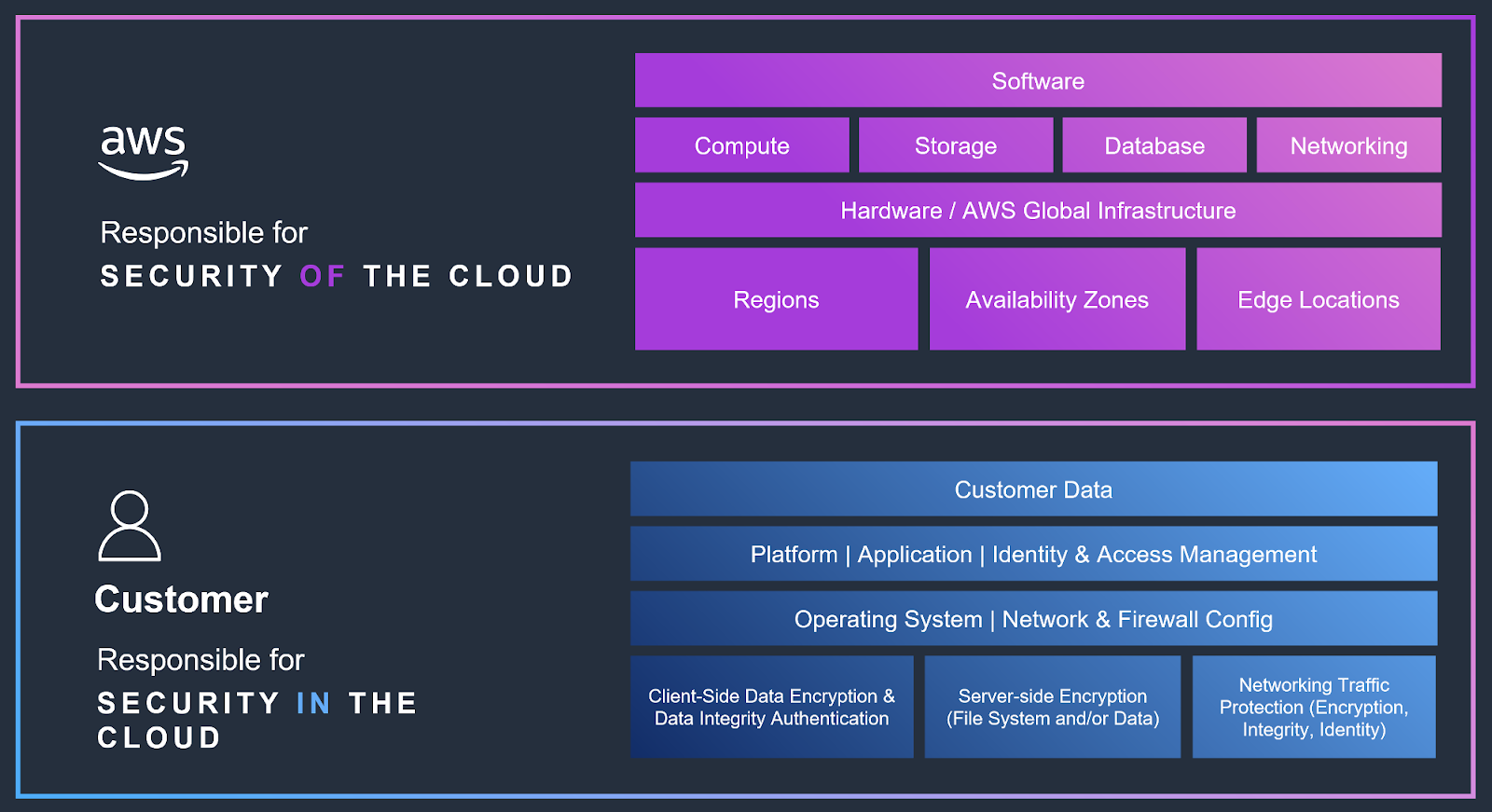
The Shared Responsibility Model is fundamental to incident response within AWS environments. It clearly defines the division of security responsibilities between AWS and the customer, influencing how incidents are handled and managed. AWS is responsible for the security of the cloud itself, encompassing the infrastructure and foundational services. Customers are responsible for security in the cloud, including data, applications, operating systems, and network traffic.
In incident response, this distinction specifies which party is responsible for investigating and remediating different aspects of a breach. AWS would address issues related to infrastructure vulnerabilities or service disruptions, while customers must manage flaws involving compromised data, misconfigurations, or application exploits. This model ensures clarity and cooperation during incident handling, with both AWS and the customer playing distinct but complementary roles in securing the overall environment.
Structure of an AWS organization
It is recommended that users set up an organizational structure for their AWS account that includes one organization unit (OU) for security and one for forensics.
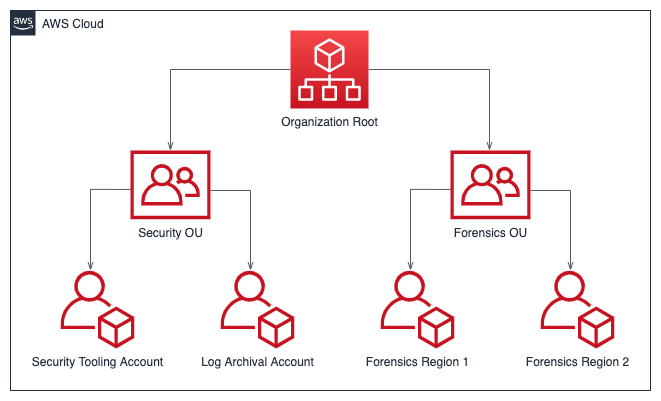
Having separate OUs for security and forensics in AWS organizations offers several advantages for incident response:
- Separation of duties: The security OU can focus on proactive security measures and tools, while the forensics OU can concentrate on reactive investigation and analysis.
- Access control: Different permission sets can be applied to each OU, limiting access to sensitive forensic tools and data. This helps maintain the integrity of forensic evidence.
- Resource isolation: Forensic activities can be conducted in a separate environment, reducing the risk of contaminating production systems.
- Confidentiality: This organization model helps maintain the confidentiality of investigations.
- Cost tracking: Separate OUs allow for easier tracking and allocation of costs related to security operations versus forensic activities.
- Scalability: The forensics OU can be scaled independently based on investigation needs without affecting other security resources.
- Audit trail: Actions taken in the forensics OU can be more easily tracked and audited separately from regular security operations.
- Reduced blast radius: If a security breach occurs in one OU, the impact on the other OUs can be minimized.
- Bypass service quota exhaustion: If a threat actor reaches the quota limit for a service, this separation of OUs does not prevent the creation of resources (e.g., EC2 instances) to perform investigations.
Incident response phases and AWS services
A comprehensive AWS incident response plan should encompass several phases, as shown below.
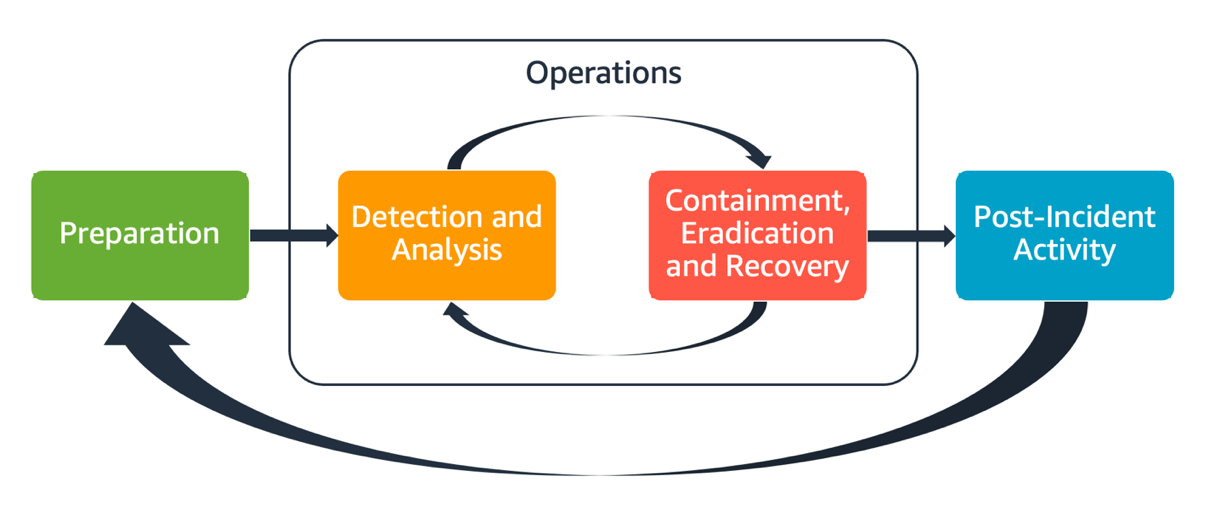
This plan employs multiple AWS services during these phases to perform a thorough threat investigation and response:
- AWS CloudTrail for logging API activity
- Preparation: It is crucial to properly enable logging of data events for specific AWS services, such as S3. More details on this can be found later in this article.
- Detection and analysis: CloudTrail is the primary source of logs in AWS. Its logs can be forwarded to third-party software that leverages detection rules to alert users to suspicious API activity. EventBridge can also be used to trigger resources of other services (such as Lambda functions or SNS topics) based on patterns of CloudTrail logs.
- Amazon Athena for querying logs and data analysis
- Preparation: It is helpful to set up partitioned Athena tables and prepare query templates that will be useful during investigations.
- Detection and analysis: Athena can be used to conduct an in-depth analysis of various log types using SQL queries.
- Amazon CloudWatch for monitoring and alerting
- Preparation: Configure AWS services to send logs to CloudWatch and set alarms for possible suspicious behaviors. CloudWatch creates a log group that will store events as log streams. It is also suggested to create anomaly detectors for sensitive log groups. Anomaly detection uses machine learning algorithms to train a model on a metric's expected values and possibly alert for divergent behaviors.
- Detection and analysis: CloudWatch logs may contain much more information about an event compared to CloudTrail logs. This makes CloudWatch a critical service for the analysis phase of incident response.
- Amazon GuardDuty for detecting and investigating threats
- Preparation: Enable GuardDuty in the regions you want to protect, leveraging its threat detection capabilities. Additional protection options can be enabled, such as malware protection for EC2 instances or S3 buckets. There is also Extended Threat Detection, which identifies suspicious patterns in sequences of multiple events.
- Detection and analysis: The GuardDuty dashboard displays a list of findings, which can be grouped by severity, finding type, affected resource, and other categories. By opening one finding, you will see many details about the potential threat, which you can then investigate further.
- AWS Config for resource configuration management and change tracking
- Preparation: Config proves to be a valuable asset during security incident investigations. Thus, during this phase it should be enabled in all regions where you have resources, with your resources appropriately configured to your organization’s requirements.
- Detection and analysis: This service continuously monitors and records your AWS resource configurations, allowing you to track changes over time. This historical view of your infrastructure provides crucial context when analyzing security events. In this phase, Config can be leveraged to identify configuration changes, assess compliance state, reconstruct past states, and provide a detailed audit trail of resource configurations if unauthorized changes were made.
- AWS Security Hub for security posture management
- Preparation: Security Hub acts as a central hub for security best practices and standards compliance. It allows you to establish a baseline security posture by aggregating findings from various AWS services and third-party tools. By enabling Security Hub and its integrations during this phase, you lay the groundwork for efficient detection and analysis.
- Detection and analysis: AWS Security Hub aggregates and prioritizes security findings from various AWS services, including Amazon GuardDuty, AWS Config, and AWS IAM Access Analyzer. This aggregation helps you gain a unified view of your security and compliance status, enabling faster identification of potential incidents. Security Hub also provides actionable insights and remediation guidance to help you investigate and respond to security issues effectively.
- IAM for access control and user identity management
- Preparation: Establishing appropriate identity and access management (IAM) roles and permissions for incident response procedures is essential during this phase. These roles will be utilized to access services and resources across accounts.
- Detection and analysis: IAM Access Analyzer monitors for permission changes in resource policies and generates findings based on risky patterns. It can identify external, internal, and unused access to critical resources, helping users to fix dangerous configurations in real time.
The subsequent stages depend on the impacted services:
- Containment is a critical step aimed at limiting the scope and impact of an identified incident. This involves isolating affected resources, such as EC2 instances or S3 buckets, by modifying security group rules, network access control lists (NACLs), or IAM policies.
- Eradication focuses on removing the root cause of the incident and eliminating any implanted malware or vulnerabilities that were exploited. This may involve patching vulnerable systems, removing malicious software, revoking compromised credentials, or reconfiguring misconfigured resources. During eradication, it’s essential to ensure that the attacker is completely cut off from the AWS environment, meaning no access (like backdoors) is left within the perimeter.
- Recovery involves restoring affected systems and services to their normal operational state. This may include restoring data from backups, redeploying application components, or lifting restrictions that were implemented during the containment phase.
- Post-incident analysis aims to identify the root cause of the incident, evaluate the effectiveness of the incident response process, and develop recommendations for improvement. This includes documenting the incident timeline, actions taken, and any shortcomings in the response. Implementing the lessons learned from the post-incident analysis helps to strengthen the organization's security posture and improve its ability to handle future incidents in the AWS environment.
Investigating incidents in AWS
Every investigation of an incident is a multi-stage journey where we want to track and understand:
- the means of initial access
- all impacted resources
- all impacted identities
- possible lateral movement into other environments
- possible persistence techniques used by the attacker to survive our attempts to cut them off from our infrastructure
The success of those stages depends on the preventive precautions we took to prepare our AWS account for any incident. A comprehensive logging capability is the main ingredient for a proper investigation and response.
Open source MCP server for AWS incident response
Throughout the investigation steps below, we will mention multiple open source tools for incident response, including AWS-IReveal-MCP, an MCP server developed by the Sysdig Threat Research Team. It integrates with the previously mentioned AWS services. You can think of it as an assistant to help you during the analysis of suspicious activity. It will also propose remediations based on the investigation discoveries.
AWS CloudTrail
If you’re concerned there was an issue with your AWS account, AWS CloudTrail would likely be the first place you would look to get an idea of what happened.
When creating a trail, it defaults to enabling logging only of management events, not data events, network activity events, or Insights. Those can be enabled with an additional cost.
- Data events are data plane operations that happen at the resource level. For instance, operations on files in S3 buckets, such as uploading, downloading, or deleting a file, are data events. Here is the list of data events for each AWS service. If an incident impacted a service without data events enabled, it may be challenging to investigate properly.
- Network activity events provide visibility into management and data plane operations performed within a VPC. Those events are supported for specific services. You can choose which service to enable by configuring advanced event selectors. It is possible to specify optional event selectors for eventName, errorCode, and vpcEndpointId to log only specific scenarios. For example, if you are using VPC Endpoints, you may be interested in logging network activity with the error VpceAccessDenied, due to violating a VPC endpoint policy. Here is the list of supported services, with examples of advanced event selector configurations.
- Insights are indicators of unusual behavior based on API call volume or error rates. Insights are helpful because they highlight significant differences compared to the account's typical usage patterns.
It’s a good practice to set up an organization trail instead of one trail for each member account. Since we do not want to miss any event in any region, the trail should be multi-region. You should also protect the trail logs stored in the S3 bucket by configuring Object Lock.
CloudTrail provides basic filtering using the Event history, which calls the LookupEvents API. This is a good starting point for investigating suspicious activity. The following screenshot shows how AWS-IReveal-MCP works, using a sample prompt.

The MCP server running with Cline
We can even ask to go through the operations performed by a role or set of roles with a specific naming pattern, as shown below:

The MCP server running with Claude Code
We utilized Stratus Red Team to conduct adversary emulation tests here. The LLM correctly pointed it out:

When investigating CloudTrail logs, here are a few key points to keep in mind:
- If the field sessionCredentialFromConsole is present, the event was generated from the web console.
- If the field ec2RoleDelivery is present, the event was generated from a principal that got credentials from the IMDS of an EC2 instance. The value says whether that instance was using IMDSv1 or IMDSv2.
- If the log contains invokedBy:AWS Internal (usually with sourceIPAddress:AWS Internal and userAgent:AWS Internal), the event was generated by AWS. This does not necessarily mean that the event should not be considered malicious. For example, an attacker who performs a SwitchRole from a compromised account to another account in the organization will cause an AssumeRole with invokedBy:AWS Internal.
- The value of userAgent can be arbitrarily set when making the request.
- In cross-account requests to access resources, the value of recipientAccountId is the account ID of the resource owner, while userIdentity.accountId is the ID of the account making the request.
- If the field vpcEndpointId is present, the request was generated from a VPC. In these cases, the sourceIPAddress is the VPC's IP address and can be private. Attackers may use a technique described here to spoof their IP address using VPCs.
CloudTrail logs can be queried using SQL for more granular searches with CloudTrail Lake or Amazon Athena. Here are some of the key differences between the two services:
- CloudTrail Lake ingests events into immutable data stores, whereas Athena queries raw JSON (or compressed) log files directly from S3, requiring users to build SQL tables.
- CloudTrail Lake provides two retention options: One keeps events in a data store for up to 10 years, and the other keeps events for up to seven years. Athena, instead, relies on S3 lifecycle policies for retention.
- CloudTrail Lake has a more limited SQL syntax than Athena.
- Both CloudTrail Lake and Athena charge for the number of bytes scanned per query. However, partitioning can dramatically reduce the amount of data scanned, yielding great cost benefits. Athena provides users with complete control over partitioning, while CloudTrail Lake manages internally how events are organized in the data stores.
For the purposes of this article, we will use Athena.
Amazon Athena
Partition projection is a great way to reduce operational overhead. AWS-IReveal-MCP
implements the query shown in the documentation to create a table that uses partition projection on CloudTrail logs from a specified date for a single AWS region. Now everything is ready to start investigating some suspicious activity using Athena. One effective template for queries is the following:
WITH flat_logs AS (
SELECT
eventTime,
eventName,
userIdentity.principalId,
userIdentity.arn,
userIdentity.userName,
userIdentity.sessionContext.sessionIssuer.userName as sessionUserName,
sourceIPAddress,
eventSource,
json_extract_scalar(requestParameters, '$.bucketName') as bucketName,
json_extract_scalar(requestParameters, '$.key') as object
FROM <TABLE_NAME>
)
SELECT *
FROM flat_logs
WHERE date(from_iso8601_timestamp(eventTime)) BETWEEN timestamp '<yyyy-mm-dd hh:mm:ss>' AND timestamp '<yyyy-mm-dd hh:mm:ss>'
--AND eventname IN (GetObject, 'PutObject', 'DeleteObject')
--AND userName = 'adminXX'
--AND sessionUserName = '<ROLE_NAME>'
--AND principalId LIKE 'AROA<xxxxx>:%'
--AND arn LIKE '%user/admin%'
--AND eventSource = '<SERVICE>.amazonaws.com'
--AND sourceIPAddress LIKE '<x.x.x.x>'
--AND bucketName = '<BUCKET_NAME>'
--ORDER BY eventTime DESC
LIMIT 50;
The query conditions are commented in this template, so you can uncomment the ones you need based on the search you plan to do.
Below are some examples of using AWS-IReveal-MCP with Athena tools.
Prompt:
Has any S3 data event occurred on buckets with name containing 'customers' in eu-central-1 in the last 24 hours?
for Athena queries use s3://pallas-athenas/ in us-east-1 as output bucket
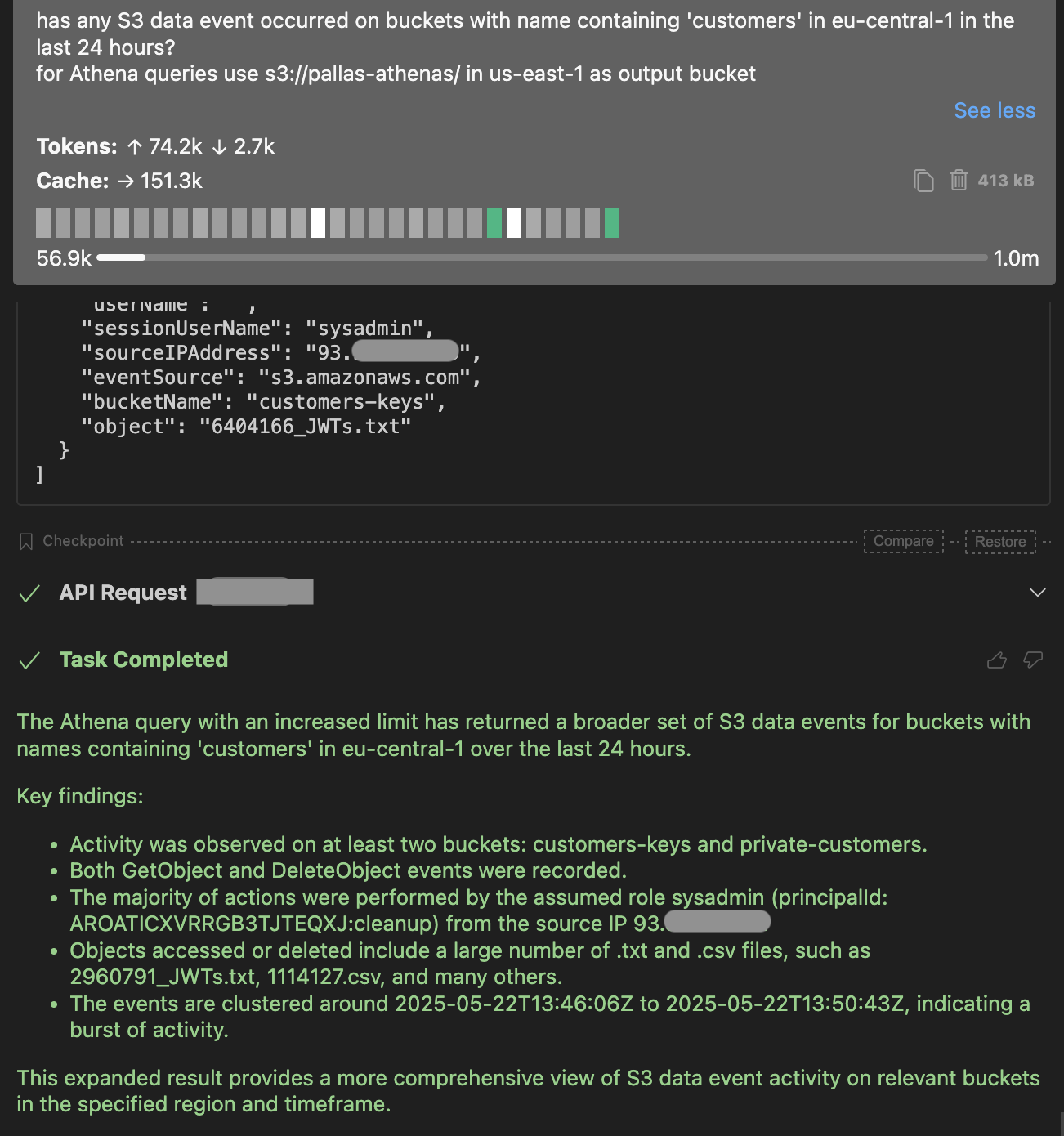
From this, we’ve already received crucial information:
- Two critical buckets were affected: “customers-keys” and “private-customers”.
- Many files were downloaded and deleted, a typical pattern for ransomware attacks.
- We know the IP address those API calls originated from, meaning we can investigate other possible activity from the same IP. The Athena query template implemented in AWS-IReveal-MCP allows that.
- The identity responsible for the activity is the role “sysadmin”, which the attacker assumed with the session name “cleanup”. Now our investigation should go through the following questions:
- After we attached the AWSDenyAll policy to that role, was the attacker able to maintain persistence from that role? For instance, could they assume another role or generate temporary credentials?
- What are the permissions of that role? Did the attacker target other services or identities with those permissions?
- Who can assume this role (i.e., what are the trusted identities in the trust policy)?
- What is the role used for? Is it the role of an EC2 instance profile? In this case, the attacker may have taken control of it via IMDS; therefore, no AssumeRole is needed. Otherwise, it is crucial to retrieve the log of the AssumeRole called by the attacker. The Principal ID in the logs of the API calls generated during the attack must match the value of responseElements.responseElements.assumedRoleId in the log of the AssumeRole. In our case, that is “AROATICXVRRGB3TJTEQXJ:cleanup”.
For additional Amazon Athena queries that cover a variety of attack scenarios, look at the open source repository aws-incident-response.
Amazon CloudWatch
Many AWS services can be configured to send logs to Amazon CloudWatch. Depending on the service settings, those logs can potentially reach very high volumes. Enabling them can make a massive difference in understanding what happened during an incident.
Simple Email Service (SES)
Let’s say a threat actor compromised a user or role with the permissions to call SES APIs, including those to send emails. They launched a phishing campaign from your AWS account targeting thousands of users. If SES was configured to send data events to CloudWatch, then the incident responder can retrieve a lot of helpful information about the emails that were sent. The following screenshot shows a CloudWatch log of a real attack abusing SES to send phishing emails:

As you can see, this log contains highly relevant data, including the sender's IP address, the email addresses of both the sender and the recipient, the sender’s alias, and the email subject.
We suggest a threat detection and response orchestration that can be summarized as follows:
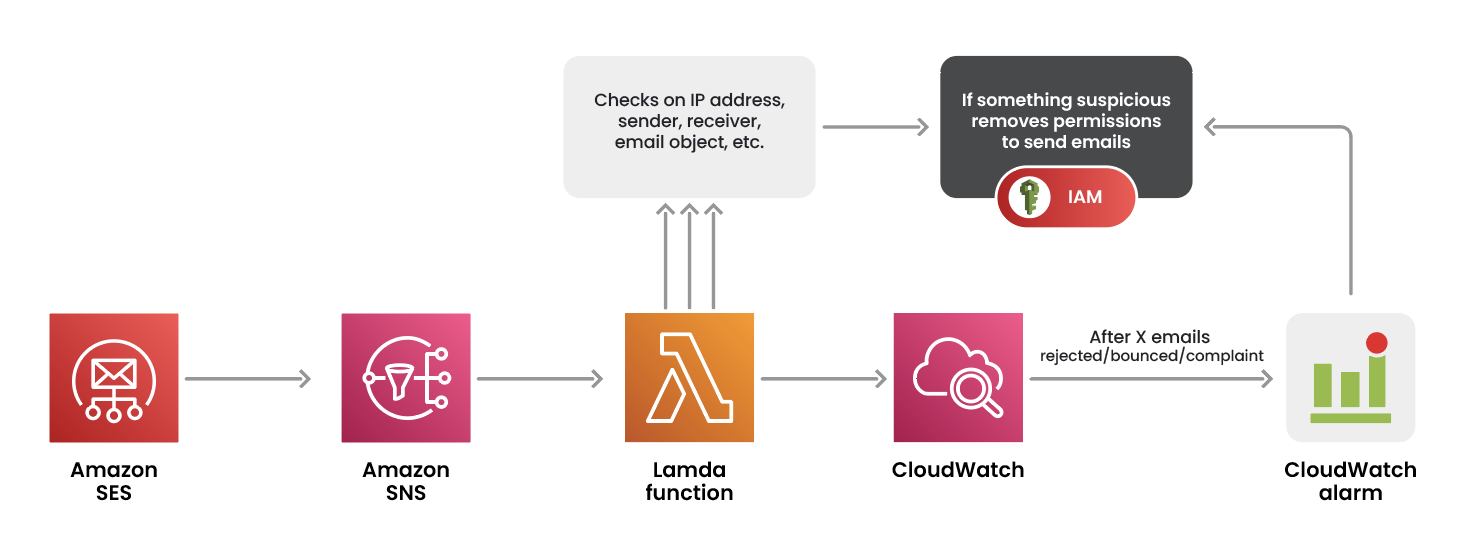
It all starts with an email sending event from SES, which is published to an Amazon Simple Notification Service (Amazon SNS) topic that triggers a Lambda function. This function performs custom checks on the fields we previously showed in the event log. You can implement whitelists of IP addresses or sender’s email addresses, for example. If one or more checks fail, there might be something suspicious with the sent email. The Lambda function can then act promptly to respond by removing permissions to the caller identity, for example. Those security checks are performed on a single email log, but what about suspicious patterns involving multiple emails? CloudWatch comes to the rescue by providing metrics such as rejected, bounced, and complaint emails. You can set up CloudWatch alarms for a threshold of emails with those metrics.
In April 2025, AWS introduced support for CloudTrail logging for email sending events. This is undoubtedly helpful when relying on CloudTrail for threat detection.
Amazon Bedrock
Another example of a service that benefits from CloudWatch logs during an investigation is Amazon Bedrock. It provides several large language models that can be invoked using different APIs, such as InvokeModel and Converse. Bedrock provides the logging of invocation events in CloudWatch. These enriched logs detail user prompts, model responses, and additional data not found in corresponding CloudTrail logs.
All this data is extremely helpful when investigating an incident like an LLMjacking attack.
We can utilize AWS-IReveal-MCP to support our analysis. For example, we could ask something like “Are there log groups related to Bedrock in CloudWatch?”
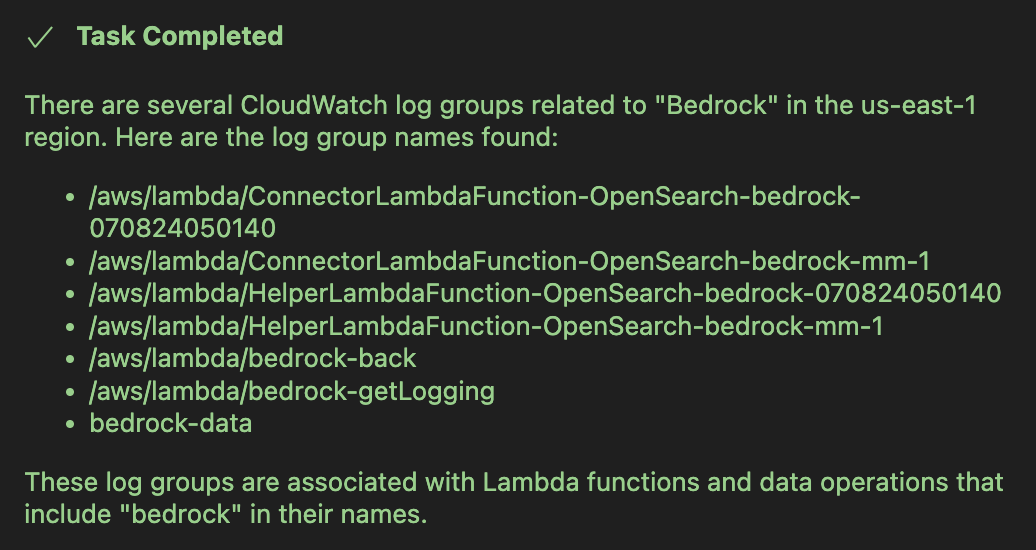
Then, we can proceed with investigating the relevant log groups using the prompt: “Let's investigate the bedrock-data log group for February 2025”.

To prevent future abuses of Bedrock, you can utilize Service Control Policies (SCPs), which enable you to manage permissions within your organization. Those policies apply to all IAM users and roles across all accounts in the organization, except for the root account.
For example, the following policy denies the invocation APIs of all Anthropic models:
{
"Version": "2012-10-17",
"Statement": {
"Sid": "DenyInferenceForAnthropicModels",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:*::foundation-model/anthropic.*"
]
}
}
If you don’t use Bedrock at all in your organization, you may want to deny all its APIs for all resources. This is, of course, a valuable option for any AWS service.
Investigating a compromised EC2 instance
A common method for gaining initial access to an AWS account is by exploiting a vulnerable or misconfigured web application hosted on an EC2 instance. AWS provides an Automated Incident Response and Forensics Framework, as well as an Automated Forensics Orchestrator, for automating the forensic analysis of EC2 instances.
These include the following essential steps needed to set up the analysis:
- Remove the compromised instance from its autoscaling group, if it is part of one group.
- Snapshot all EBS volumes attached to the instance.
- Record all instance metadata (public and private IP address, AMI details, subnet, etc.)
- Remove all attached security groups and replace them with an isolation security group that denies all inbound and outbound connections.
- Attach an IAM role that disallows all access to APIs.
After isolating the machine, its volume snapshots should be shared with the forensic account. Then, new EBS volumes have to be created from those snapshots and attached to an EC2 instance running in a private subnet within a VPC for the investigation.
Now we can proceed with analyzing the machine. Several open source tools can be used based on the operating system of the machine:
- LiME, Linux Memory Extractor.
- Volatility, used for memory forensics.
- The Sleuth Kit, a toolset for analyzing disk images. Among the many functionalities, it can make a “diff” between the file system of the current machine and the file system of the original AMI. This can be very helpful in detecting even the most subtle changes that attackers may have made to the machine.
- ssm-acquire, developed by Mozilla to acquire and analyze the memory of an EC2 instance using SSM (Systems Manager).
- cloud-forensics-utils, developed by Google to set up forensic analysis on EC2 instances. It implements functions to isolate the virtual machine, create EBS snapshots, and attach them to an external forensic instance or copy them to an S3 bucket using a script that utilizes dc3dd, a patched version of the disk backup tool dd. It also installs several forensic tools in the instance used for analysis, including The Sleuth Kit.
Automating threat detection and response can be extremely helpful when employing a high volume of EC2 instances. A finding from GuardDuty can trigger the framework provided by AWS to analyze the affected machine, alert the account owner, and send them a report of the analysis. The framework can be further enriched with additional tools for a more in-depth analysis.
Let’s consider an EC2 instance we want to investigate. After installing cloud-forensics-utils, we run the following command to copy the volume from the account with the instance to a different forensics account:
cloudforensics aws 'us-east-1c' copydisk --volume_id='vol-0f1af2a470d420440' --src_profile='hp2-adminB' --dst_profile='default'
Then, the following command runs a new EC2 instance in the forensics account with the provided AMI, 4 CPUs, a 50 GB volume, and the volume copied from the compromised instance.
cloudforensics aws 'us-east-1c' startvm 'vm-forensics' --boot_volume_size=50 --cpu_cores=4 --ami='ami-020cba7c55df1f615' --attach_volumes='vol-0db527dfcd85612f8' --dst_profile='default'
Now we can connect to the new EC2 instance to analyze the compromised volume.
We can start with fls, which is part of The Sleuth Kit, to enumerate every file and directory entry on the given device:
sudo fls -r -m / /dev/xvdf1 > full.bodyThe output file is then input to mactime to build a chronological “MAC timeline” (Modify, Access, Change) in a CSV file:
sudo mactime -z UTC -d full.body > timeline.csvFor a richer, event-based timeline, we can also leverage Plaso, which is included in the forensic tools automatically installed in the instance. The following command scans hundreds of artifact sources (filesystem timestamps, Windows event logs, macOS logs, browser history, etc.) and writes events to /mnt/plaso.dump.
sudo log2timeline.py /mnt/plaso.dump /dev/xvdf1Finally, we can create an HTML or CSV file with a timeline by running:
sudo psort.py -o dynamic -w plaso_timeline.html /mnt/plaso.dumpThis procedure enables us to analyze any changes in the filesystem and reconstruct a complete timeline of activity on the suspect volume. By pulling raw filesystem metadata into a “body file” and then timestamp‐sorting it using SleuthKit’s fls and mactime, you see every file’s create/modify/access/change times in one CSV. And by ingesting the same raw device into Plaso (log2timeline and psort), you layer on hundreds of other artefact sources into a single timeline.
The following screenshot is an excerpt from the output of psort, showing the evidence of someone trying to brute-force the SSH login of a machine.
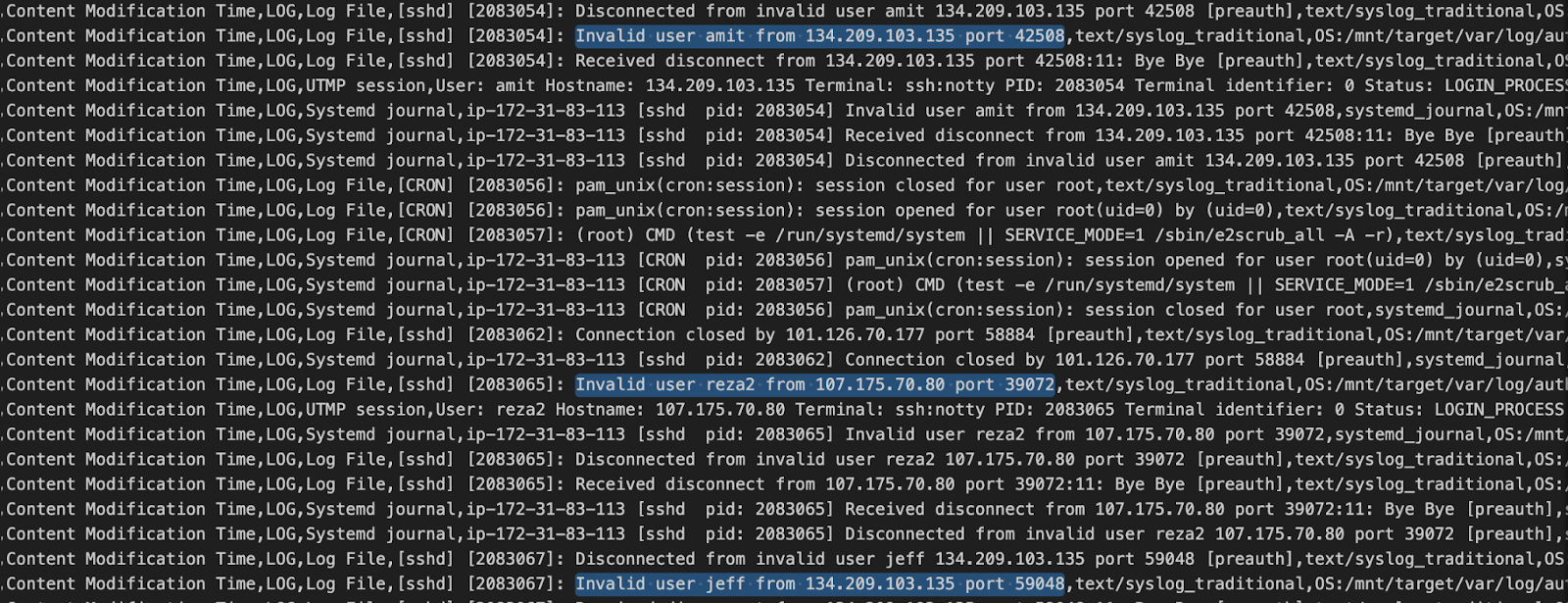
That information is retrieved by psort because the /mnt/target/var/log/auth.log.1 file is getting updated for each login attempt.
A related idea that can be helpful is comparing the current filesystem with the original AMI’s filesystem to look for suspicious changes.
Analyzing network traffic for malicious activity
VPC Flow Logs capture network traffic going to and from network interfaces in your VPC, making them a critical resource for detecting malicious activity. You can choose to deliver these logs to CloudWatch, an S3 bucket, or Amazon Data Firehose (in the same or different account). CloudWatch provides the capability to configure alarms based on various metric filters such as source and destination ports, source and destination addresses, protocol, and others. Here is an example of how to create an alarm for 10 or more rejected SSH connection attempts to an EC2 instance within one hour.
After this, you can use Amazon Athena to analyze network traffic with SQL queries. Look for unusual patterns such as connections to unfamiliar IP addresses, high volumes of data transfer to external locations, traffic on ports that are not typically used, or communication patterns that deviate significantly from established baselines. Correlate these findings with other security logs, such as CloudTrail, to identify the source and context of the suspicious network activity. Pay close attention to rejected connections, as they can indicate attempts to probe your network for vulnerabilities. Regularly review and analyze Flow Logs to build a strong understanding of your normal network behavior. When you know your organization’s baseline behavior, you can effectively identify deviations that could signify malicious intent.
Mitigate common persistence techniques
Federation credentials
The first response to detecting that an IAM user’s keys have been compromised is often to deactivate or delete those keys. However, this does not prevent the attacker from misusing that user if they were able to create temporary credentials with GetFederationToken before the keys were disabled.
That API creates temporary credentials that last up to 36 hours (or one hour if the user is the root user). When calling it, you can pass a session policy (managed or inline). The resulting session permissions are the intersection of the IAM user policies and the provided session policies.
Revoke token
You should revoke the session permissions by attaching a deny-all policy to the compromised user with the “aws:TokenIssueTime” field. What follows is an example policy reported here:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Deny",
"Action": "*",
"Resource": "*",
"Condition": {
"DateLessThan": {"aws:TokenIssueTime": "2014-05-07T23:47:00Z"}
}
}
}
By setting a date following the creation of the federation credentials, this policy denies all permissions. Additionally, if your environment does not utilize federated users, you may want to monitor for calls to GetFederationToken and implement appropriate detection rules.
Backdoor role
A common method for attackers to maintain access to an AWS account is to backdoor an IAM role. This can be pursued by modifying the trust policy of a role to specify that it can be assumed by an identity belonging to the attacker’s AWS account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<ATTACKER_ACCOUNT_ID>:user/evil_user
]
},
"Action": "sts:AssumeRole"
}
]
}
You should have a security mechanism in place that monitors roles’ trust policies and alerts for those that can be assumed by an external account ID.
Another persistent threat is posed by a set of roles that can assume one another. An attacker who compromises one of those could then assume another role to refresh credentials and continue doing so to maintain access. According to the documentation of the role chaining, the duration of those credentials can be set to a maximum of one hour. This method is known as role chain juggling.
EC2 instance
To manage their permissions, EC2 instances use instance profiles, which are containers for an IAM role. Those permissions are needed to allow the instance to access AWS services. To retrieve the session credentials of an instance profile, you should call the endpoints provided by IMDSv1 or IMDSv2, based on which one is configured on the instance.
An attacker who discovers an RCE or SSRF vulnerability in a web application running on an EC2 instance can exploit it to steal those credentials. This allows the attacker to use the permissions of the instance profile and maintain access to the victim’s AWS account.
Proper runtime detection on the machine is necessary to detect someone stealing credentials via IMDS promptly. That operation does not generate an AssumeRole event; thus, you cannot rely on monitoring for suspicious calls to that API. Instead, as previously mentioned, we can rely on the field ec2RoleDelivery in the CloudTrail logs. That field shows if the credentials used to call an API were generated with IMDSv1 or IMDSv2.
After detecting suspicious events from an EC2 instance role, the first response is, once again, to attach a deny policy to that role and revoke previous sessions. Then, you should consider disassociating the compromised instance profile from the instance by calling DisassociateIamInstanceProfile. After remediating the root cause of the attack (i.e., vulnerability or misconfiguration of the web app), you should create a new instance profile (with a new set of keys) to associate with that EC2 instance.
User data
Another way attackers can maintain persistence in an EC2 instance is by using user data. They contain commands that will be run as root upon starting the machine. Should an attacker have compromised an identity with the ModifyInstanceAttribute permission, they can modify the user data of an EC2 instance and insert malicious code. Be aware that the instance should be stopped to allow the modification of its user data. Thus, the following sequence of events should be monitored as it can be suspicious: StopInstances -> ModifyInstanceAttribute -> StartInstances.
Resource-based techniques
The previous persistence techniques can be considered operational, where the attacker backdoored an IAM role or runtime instance to maintain control over a set of services or resources. Another type of persistence is tied to resources, such as RDS databases,
S3 buckets, Lambda functions, and SQS queues. Backdooring those resources allows attackers to keep access to data passing through them without having access to any identity within the victim’s AWS account. Mitigation and response strategies may differ based on the affected resource:
- Amazon RDS: Take a manual snapshot and export parameter group settings.
- Amazon S3: Copy the policy JSON and object ACLs.
- AWS Lambda: Download the deployed code package.
- Amazon SQS: Export queue attributes and policy.
Then, you should:
- Compare the snapshot or state of the resource against the last known-good infrastructure as code (IaC) definition, which helps in identifying unauthorized changes.
- Detach public endpoints or restrict networks (e.g., tighten RDS security group).
- Remove any external principals from resource policies immediately.
Conclusion
Incident response is not a static process; it's a dynamic and evolving discipline that requires constant refinement to remain effective against ever-changing threat landscapes. The lessons learned from each incident provide invaluable insights that must be integrated into the current incident response plan. This continuous feedback loop ensures that the organization's defenses are constantly adapting and improving. The following areas are particularly critical for fostering continuous improvement:
- Automating incident response actions where possible: Identifying repetitive tasks and processes within the incident response workflow and automating them can dramatically enhance efficiency and consistency. A proper threat detection measure should be implemented to raise near-real-time alerts. It can be combined with some automated response actions. For example, an alert on an EC2 instance could trigger the automation to isolate the instance and create a snapshot for forensic analysis.
- Regular security audits and penetration testing: Proactive security assessments are essential for identifying vulnerabilities and weaknesses before attackers can exploit them. Regular security audits, both internal and external, can review configurations, policies, and procedures against industry best practices and compliance requirements. Penetration testing, on the other hand, simulates real-world attacks to identify exploitable vulnerabilities in systems, applications, and network configurations. One very effective tool for simulating real-world attacks is Stratus Red Team. Testing your detections is crucial to identifying and resolving potential issues.
- Training and awareness for incident response teams: The most sophisticated tools and technologies are only as effective as the people using them. Continuous training and awareness programs are paramount for ensuring that incident response teams are well-equipped to handle a wide range of security incidents. Fostering a strong security culture throughout the organization contributes to a more resilient overall security posture.
By committing to continuous improvement and leveraging available resources, organizations can build highly effective incident response capabilities in AWS, minimizing the impact of security incidents and protecting their critical assets in the cloud.