Leveling up Kubernetes Posture: From baselines to risk-aware admission



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

For many organizations, Kubernetes posture management tends to start with a small set of common guardrails rather than a deeply opinionated security model.
Some teams rely entirely on default Kubernetes behavior, trusting cluster access controls and hoping developers "do the right thing." Others adopt Pod Security Standards (PSS) as a baseline, using Kubernetes-native guardrails to block the most obviously unsafe workloads.
These approaches are common because they are:
- Built into the Kubernetes ecosystem
- Relatively easy for platform teams to adopt
- Low friction to apply across multiple clusters
In practice, this works reasonably well as an initial posture. Obvious misconfigurations are blocked, expectations are set, and teams can move forward without introducing heavy operational overhead.
Where Kubernetes baselines start to fall short
Modern Kubernetes environments look very different from the environments these baseline controls were originally designed for. Clusters are no longer just running stateless application workloads. They routinely include:
- Privileged infrastructure components
- Third-party software with opaque or poorly documented security requirements
- Workloads that interact directly with cloud APIs, identity systems, and sensitive data
Pod Security Standards are intentionally coarse-grained. They do a good job answering “is this generally safe?” but they aren’t designed to answer more contextual questions — such as whether something is safe here, safe for this workload, or what risk is being accepted by allowing it in the first place.
The result is a familiar operational tradeoff. Teams either relax enforcement broadly and accept the risk, or they enforce strict baselines and slowly accumulate a growing list of exceptions as real workloads break. Over time, those exceptions become the rule, and the original security signal loses its value.
Why posture hasn’t evolved (yet)
Pod Security Standards, enforced through Kubernetes’ built-in Pod Security Admission (PSA), have become the default way many teams introduce admission control. PSA is predictable, well understood, and intentionally limited in scope.
The challenge appears when teams reach the boundaries of what PSS and PSA are designed to express. As environments mature, posture decisions become more contextual, and the tradeoffs become harder to manage:
- Limited expressiveness:
PSA evaluates pods against broad security levels, but it cannot reason about workload identity, ownership, environment, or intent. - Coarse enforcement boundaries:
Decisions are typically made at the namespace level, making it difficult to allow risky capabilities in narrowly scoped, well-understood cases without opening the door more broadly. - Exception pressure:
As real workloads accumulate, teams are forced to either loosen enforcement or carve out namespaces that effectively bypass meaningful controls.
Some teams explore more flexible admission frameworks to regain expressiveness. Open-source tools like OPA Gatekeeper and Kyverno provide powerful building blocks, but they also require significant policy design, testing, tuning, and ongoing maintenance. For many organizations, that added complexity becomes a barrier rather than a clear next step.
The result is a natural plateau. PSA remains a safe, built-in baseline, while moving beyond it feels costly and risky to operate at scale.
Reframing posture as a decision point
Up to this point, Kubernetes posture has largely been treated as a static checklist: apply a baseline, enforce it consistently, and handle exceptions as they arise. That approach works when workloads are uniform and risk is easy to generalize.
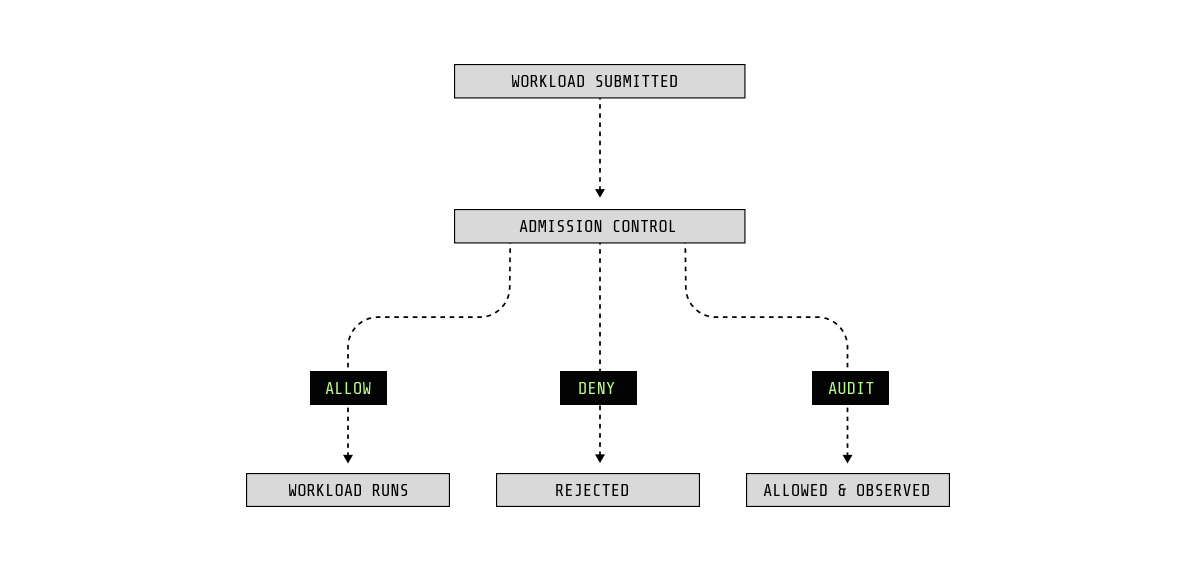
In practice, posture is not static. It is a decision that Kubernetes already makes every time a workload is created or updated.
In Kubernetes, that decision happens at admission time. Before a pod ever runs, the API server evaluates whether it should be allowed, rejected, or allowed with visibility. Pod Security Admission applies this decision using broad security levels, establishing a necessary floor. What it does not do is reason about context.
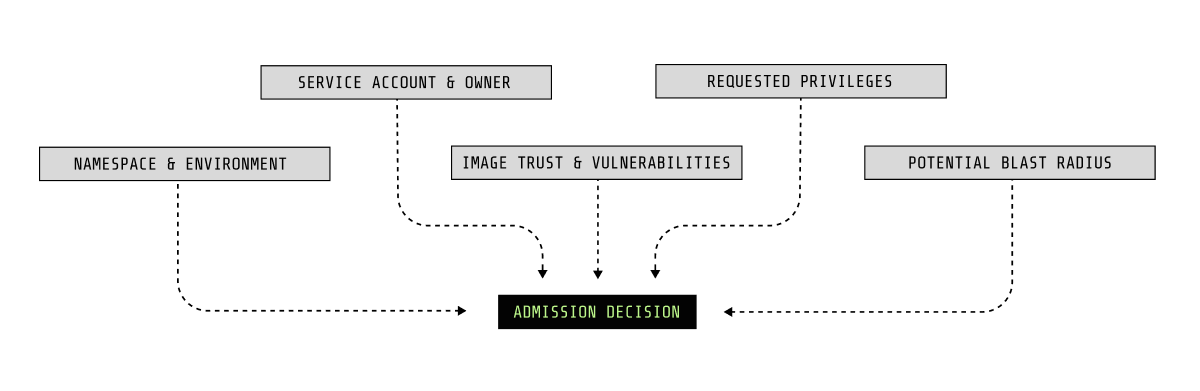
A risk-aware posture model builds on that same decision point, but expands what is considered before a workload is allowed to run. Instead of asking only whether a configuration meets a universal standard, teams can evaluate the risk of a workload in its actual environment.
At admission time, that can include questions such as:
- Where is this workload running, and what does it have access to?
- What identity does it run as, and how broadly is that identity trusted?
- What privileges or host access does it require?
- What image is being deployed, and is it known to be risky?
- If compromised, what could this workload realistically impact?
When posture is treated as a decision rather than a checklist, risky configurations are no longer simply “allowed” or “blocked” everywhere. They are evaluated in context, and enforcement becomes intentional rather than accidental.
This shift builds on Pod Security Standard, not replaces them. PSS establishes the floor. Risk-aware admission applies context on top, allowing teams to prevent unsafe states before workloads ever reach runtime, without breaking legitimate use cases.
PSA in practice: A concrete example on Amazon EKS
In theory, using Pod Security Admission is straightforward. You choose a Pod Security Standard, apply it to a namespace, and Kubernetes blocks anything that doesn’t meet that baseline. There’s nothing to install and no policy engine to operate. It is literally built into Amazon EKS.
In practice, the experience is both effective and rigid.
What PSA looks like in practice
Create a namespace and label it to enforce the restricted standard:
Command:
kubectl create namespace demo-app
kubectl label namespace demo-app \
pod-security.kubernetes.io/enforce=restrictedFrom this point on, every pod admitted to the namespace is evaluated against the same profile.
Create a deployment that requests privileged access:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
labels:
app.kubernetes.io/name: nginx-test
app.kubernetes.io/component: demo
spec:
replicas: 1
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx
image: nginx
securityContext:
privileged: trueWhen you apply the manifest, the pod is immediately rejected. The error indicates that the workload violates the restricted Pod Security Standard, and the deployment stops there.
kubectl apply -f nginx.yaml -n demo-app
Warning: would violate PodSecurity "restricted:latest": privileged (container "nginx" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (container "nginx" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "nginx" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "nginx" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "nginx" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")This is PSA working exactly as designed.
What’s missing is context. There’s no understanding of why the workload exists, who owns it, or whether the requested privilege is expected in this environment. The decision is binary and scoped to the entire namespace.
If the workload legitimately requires elevated access, the only options are to relax enforcement for everything in that namespace or move the workload elsewhere. Over time, posture drifts because exceptions pile up, not from lack of care, but from a lack of expressiveness.
Why this matters
Pod Security Admission establishes a strong, Kubernetes-native floor. It reliably blocks unsafe defaults before workloads ever run. What it does not do is reason about risk. Differentiating between “unsafe by default” and “risky but intentional” requires context that PSA is not designed to evaluate.
That gap is where teams begin looking for more risk-aware admission decisions.
Moving beyond baselines: Adding context with Sysdig
Pod Security Admission gave us a clean failure. It did exactly what it was designed to do: block a privileged container in a restricted namespace.
That’s the baseline. Now let’s replay the same deployment.
Subtlety beyond namespace
PSA is intentionally rigid. It evaluates pods against a security level at the namespace boundary. That makes it great for establishing a baseline, but it also means the decision is blunt:
- It fails in
restricted - It passes if you loosen the namespace
- And every workload in that namespace gets the same treatment
Sysdig admission control keeps the same “admission-time decision point,” but it gives you more precision in how you apply posture.
Instead of only evaluating privileged: true in a vacuum, Sysdig can scope posture decisions using things teams already have. Examples include:
- Standard Kubernetes application labels (app, component, instance)
- Helm origin to identify “this came from that chart”
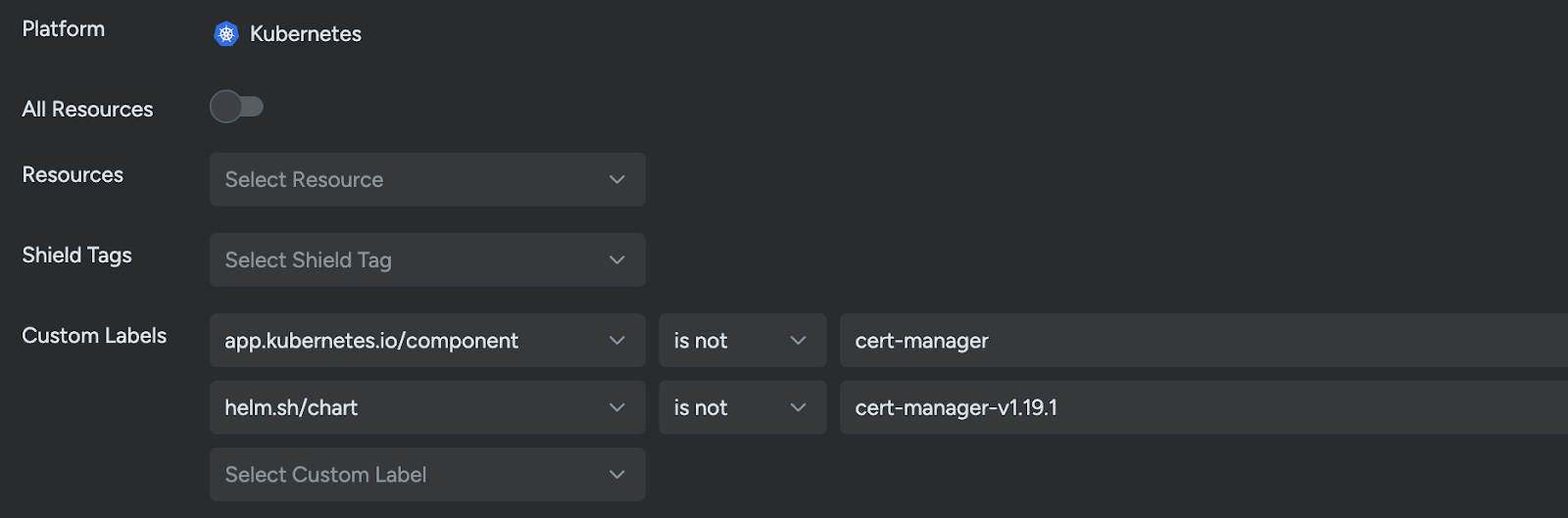
That means you’re no longer stuck with “namespace = policy.”
You can scope posture expectations to workload attributes such as labels and Helm metadata, allowing more granular enforcement across clusters and namespaces without relying solely on namespace-level boundaries.
From binary enforcement to profile-driven posture
Once posture is no longer tied strictly to the namespace boundary, something more interesting becomes possible.
You’re no longer limited to a single security level applied everywhere. Instead, you can apply different control sets to different groups of workloads.
With PSA, enforcement is effectively binary:
- A namespace enforces
restricted, or it doesn’t. - A pod violates the level, or it passes.
With Sysdig, posture can be evaluated against multiple standards and control sets, and applied selectively based on workload identity.
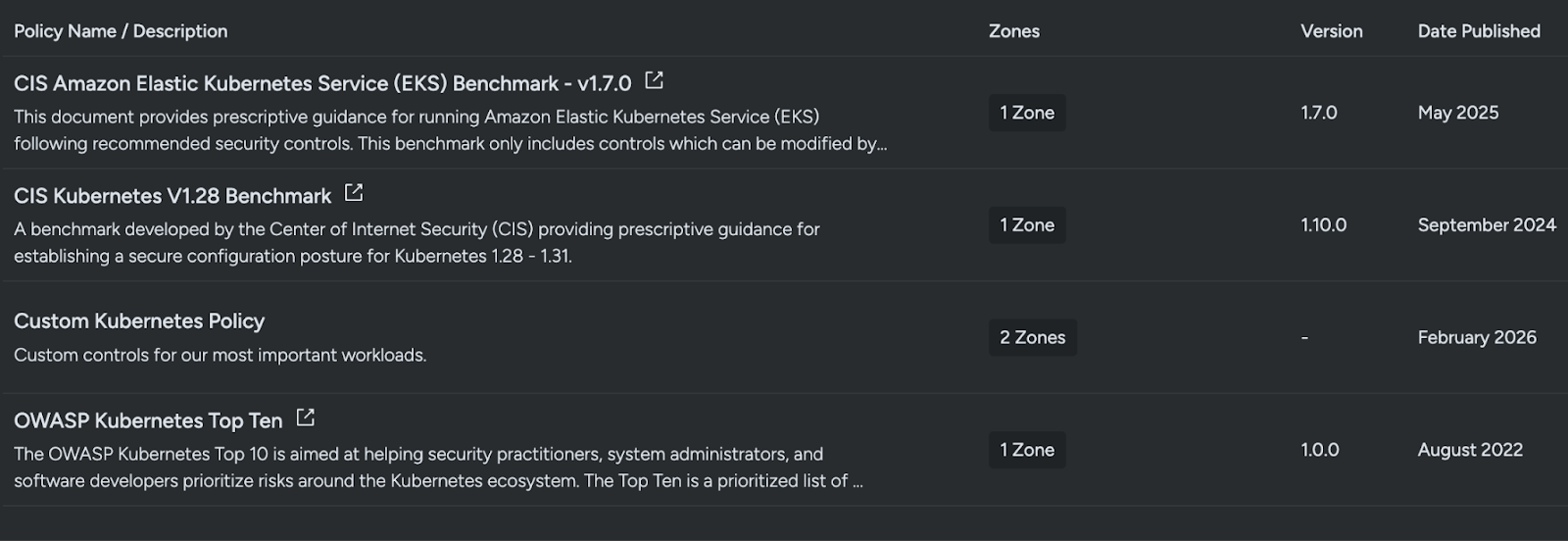
That means different resource groupings can be evaluated against completely different expectations, for example:
- Platform workloads can be evaluated against controls aligned to CIS benchmarks
- Application workloads can be evaluated against OWASP-aligned controls
- Sensitive workloads can include additional custom organizational checks
Now posture is no longer just PSS. It’s more flexible. It’s more realistic. Because real clusters aren’t uniform.
The subtlety PSA can’t express: Two privileged workloads
Imagine two pods that both request privileged access:
- A known infrastructure DaemonSet, maintained by platform engineering, deployed via an approved Helm chart
- A random application workload, deployed from an unfamiliar image, with obvious red flags
PSA sees the same thing for both:
privileged: true
Sysdig can still start with that signal, but it can reach a different decision because it can distinguish between workloads, for example via:
- Labels and ownership metadata (platform vs app)
- Helm chart identity (known release/chart vs unknown)
Those are different risk profiles.
One might be allowed with tight guardrails because it’s understood and intentional. The other is rejected.
That’s the upgrade: posture stops being a static checklist and becomes an informed, targeted decision, without redesigning your entire namespace layout just to express intent.
Granular exceptions without losing signal
One of the operational challenges with baseline-only enforcement is exception sprawl. When a legitimate workload violates policy, teams often relax enforcement at the namespace level or create broad carve-outs that unintentionally reduce overall posture strength.
A more precise admission model allows exceptions to be scoped narrowly. Instead of disabling enforcement for an entire namespace, teams can define exceptions at a much more granular level. This can be as narrow as a single control finding for a single workload.
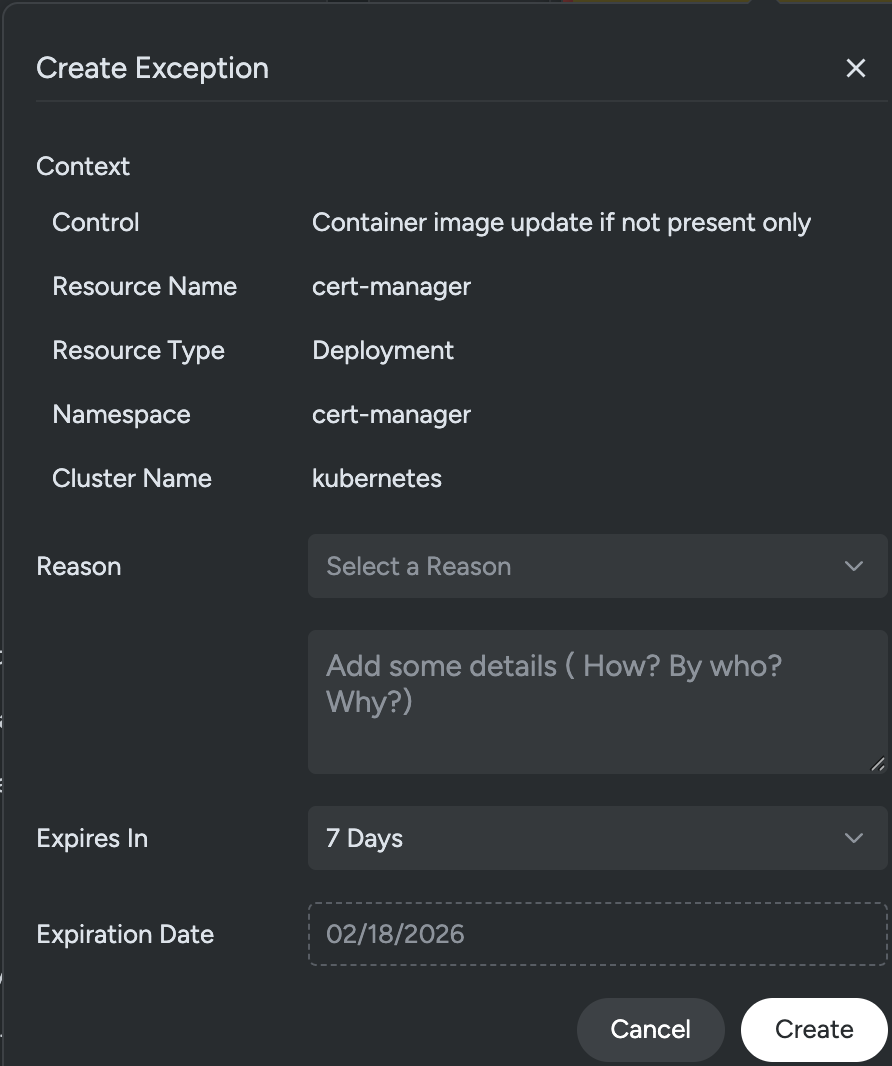
This ensures that exceptions are explicit, documented, and limited in scope. The goal is not to eliminate exceptions, but to prevent exceptions from becoming permanent policy gaps. Granularity preserves signal. It allows teams to maintain strong posture controls while acknowledging operational realities.
Vulnerability-aware admission
This is where admission control becomes more risk-informed.
Pod Security Admission does not evaluate the vulnerability posture of container images. It has no visibility into:
- Whether an image contains critical CVEs
- Whether those CVEs are exploitable
- Whether fixes are available
Sysdig admission control can incorporate vulnerability findings directly into the admission decision.
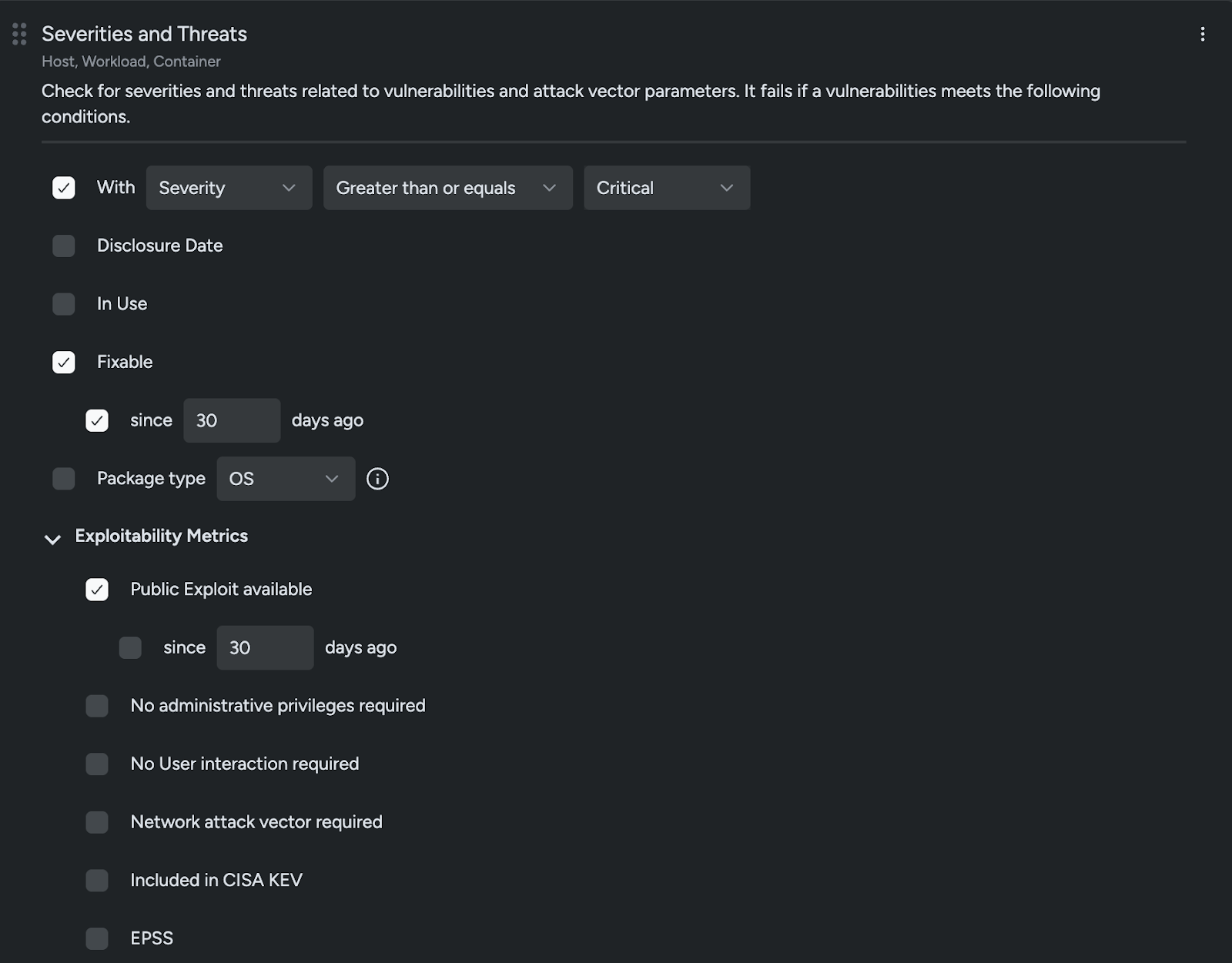
For example, policies can be defined to:
- Block images with critical vulnerabilities where a fix is available
- Block images containing specific CVEs
- Allow only images that exclude certain packages
- Require zero High+ vulnerabilities in production namespaces
Revisiting the same nginx example, the workload might be rejected not simply because it is privileged, but because:
- The image contains multiple critical vulnerabilities
- Fixes have been available for more than 30 days
- A known exploit exists
- The workload is being deployed into a production namespace
kubectl apply -f nginx.yaml -n demo-app
Error from server: error when creating "nginx.yaml": admission webhook "vac.secure.sysdig.com" denied the request:
[VM Engine] Failed checks for container nginx. Failing policies: [AC Policy]
Violations:
x Severity greater than or equal criticalThat is not a configuration-only decision. It is a risk-based posture decision.
Runtime reality
Admission control makes a decision at a specific point in time. It evaluates configuration, image risk, and deployment context before a workload ever starts. What it cannot evaluate is behavior.
A workload may satisfy every posture control and still be vulnerable to exploitation after deployment. Even well-configured, tightly restricted applications can contain software flaws, misconfigurations in dependent services, or logic errors that only surface at runtime.
In many environments, certain workloads are intentionally granted elevated privileges. That elevation may be necessary for operational reasons, but it also increases the potential impact if the workload is compromised.
Whether tightly restricted or deliberately privileged, a compromised workload can abuse its credentials, move laterally across the environment, modify its filesystem, or execute unexpected processes. These actions are not visible in the Kubernetes specification and cannot be fully determined during admission.
Posture controls prevent known unsafe states before a workload begins running. Runtime security addresses what occurs after that decision has been made.
Admission answers: “Should this workload be allowed to start?”
Runtime answers: “Now that it is running, is it behaving as expected?”
In modern Kubernetes environments, both controls are necessary. Configuration compliance reduces risk, but it does not guarantee behavioral safety.
Conclusion
Kubernetes posture often begins with practical guardrails. Pod Security Standards establish a strong, built-in baseline that blocks obvious misconfigurations and raises the overall security floor.
But as environments mature, a single enforcement level applied uniformly across namespaces becomes limiting. Workloads differ in trust, exposure, and operational needs. Effective posture requires decisions that reflect that reality.
By treating admission as a decision point rather than a static checklist, teams can move beyond binary enforcement. Posture can be aligned to workload identity, benchmark standards, and vulnerability risk. It is applied intentionally instead of uniformly.
Although admission reduces risk before workloads start, it cannot account for everything that happens afterward. That is why runtime visibility and enforcement remain essential. Kubernetes security is not a single control, but a series of informed decisions from deployment to execution.