



Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

Sysdig is doubling down on open source innovation, and part of that process is getting projects out in the open to make them better. In our Open Source Spotlight, we’ll highlight some of the exciting work our community has come up with. If you would like to be part of the next Open Source Spotlight, join community.sysdig.com and submit your exciting work to the contest!
That said, this is an experimental project where things are moving fast! Features may change, evolve, or occasionally break — so we don’t recommend using this in production just yet. If you spot something unusual, have an idea, or want to contribute, please open an issue and help us make it awesome!
Miguel De Los Santos started his journey with a simple goal: to augment Falco events with AI tools like OpenAI and Gemini. As he worked to hone his AI engineering skills, he quickly recognized a need within the Falco community. Raw Falco alerts, while crucial for security monitoring, often lacked the context and actionable guidance necessary for a rapid incident response. This insight inspired him to create Falco Vanguard. The project, which grew from a simple clone into a sophisticated, feature-rich tool, is an experimental AI-enhanced alert system designed to deliver real-time security analysis. Falco Vanguard not only provides rich telemetry but also offers advanced tooling and localized data processing to Falco users, with the ultimate goal of becoming an integral part of the Falco community, just like Falco Sidekick and Falco Talon.
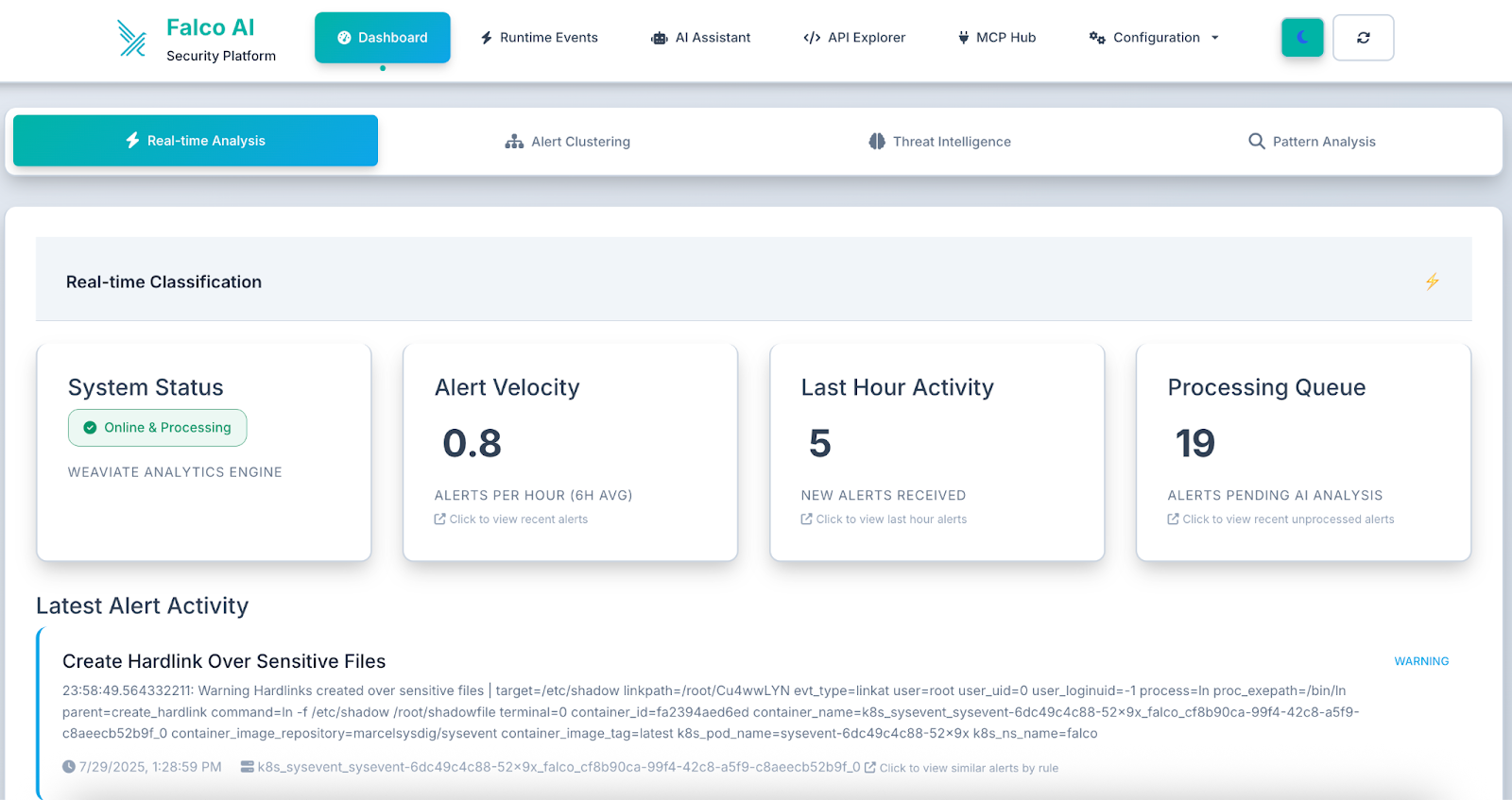
Figure 1.0 - Live monitoring of security events with real-time threat detection and analysis.
Introducing the Falco Vanguard
The Falco Vanguard is a comprehensive webhook-based solution that transforms basic Falco security alerts into actionable security intelligence. Built as a Flask application with an integrated web dashboard, this system enriches Falco alerts with AI-powered analysis using OpenAI, Gemini, or local Ollama models.
The platform provides real-time security analysis by processing Falco webhook alerts and delivering enhanced notifications to Slack channels with detailed security impact assessments, remediation steps, and suggested investigation commands.
This open source solution is available for deployment across various environments, including Docker, Kubernetes, and major cloud platforms (AWS, GCP, Azure). Organizations can use this system to:
- Transform raw alerts into actionable intelligence with AI-powered security analysis
- Reduce alert fatigue by providing context and priority guidance.
- Accelerate incident response with automated investigation recommendations.
- Maintain security awareness across teams with rich Slack notifications.
- Gain immediate insights with real-time processing of security alerts, ensuring you're always aware of emerging threats.
- Enhance threat detection accuracy through AI-powered analysis using leading models, such as OpenAI, Gemini, or Ollama, to provide intelligent context to raw alerts.
- Visualize your security posture instantly with an interactive web dashboard offering real-time alert visualization and flexible display modes.
- Centralize security operations by integrating with 15 security tools via 4 MCP protocols, all accessible from a unified dashboard.
- Enhance team collaboration and response times with analyzed alerts sent directly to Slack, promoting shared awareness and faster action.
- Achieve seamless deployment across any Kubernetes environment with automatic detection and optimization for GKE, EKS, AKS, DOKS, IBM Cloud, and local K8s.
- Optimize performance and resource allocation with dynamic configuration that intelligently adjusts storage classes and resources based on your platform.
- Ensure broad compatibility with multi-architecture support for both AMD64 and ARM64 Docker images.
- Experience intuitive and efficient security management with an enhanced UI/UX featuring a modern, responsive design.
Keep reading to learn how to:
- Deploy the Falco Vanguard in your environment
- Configure multiple AI providers for intelligent analysis
- Integrate with your existing Falco deployment
- Set up automated Slack notifications with security insights
Architecture overview
The Falco Vanguard follows a microservices architecture designed for cloud-native environments:
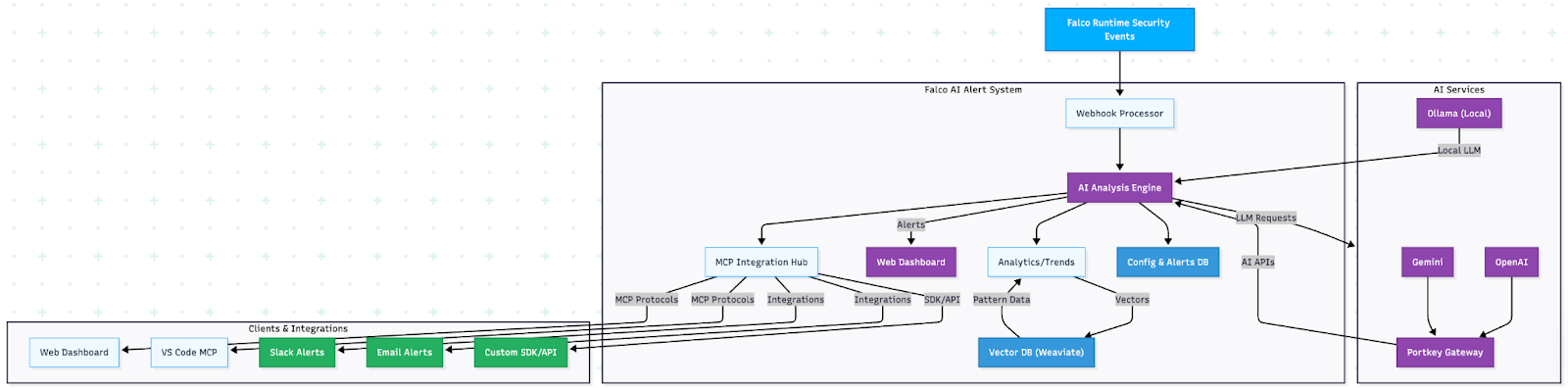
Core components
- Webhook receiver: Flask-based HTTP endpoint that receives Falco alerts
- AI analysis engine: Multi-provider AI integration for security analysis
- Web dashboard: Real-time alert visualization and management interface
- Slack integration: Rich message formatting with actionable security insights
- Database layer: SQLite-based storage for alert history and configuration
Requirements before you get started
Ensure you have the following prerequisites:
- Container runtime: Docker 20.10+ and Docker Compose
- Kubernetes (optional): v1.19+ for container orchestration deployment
- AI provider access (using Portkey): API keys for OpenAI/Gemini via Portkey, or Ollama for local inference
- Slack integration: Bot token with chat:write permissions
- Falco installation: Running a Falco instance configured to send HTTP Outputs
AI provider options
The Falco + AI Alert System is highly adaptable to organizational needs, and at this point supports three AI provider configurations:
Option 1 (Default): Ollama (Local/Privacy-Focused)
PROVIDER_NAME=ollama
OLLAMA_MODEL_NAME=llama3
OLLAMA_API_URL=http://localhost:11434/api/generateOption 2: OpenAI via Portkey (Cloud)
PROVIDER_NAME=openai
PORTKEY_API_KEY=pk-your-portkey-key
OPENAI_VIRTUAL_KEY=openai-your-virtual-key
MODEL_NAME=gpt-4Option 3: Gemini via Portkey (Cloud)
PROVIDER_NAME=gemini
PORTKEY_API_KEY=pk-your-portkey-key
GEMINI_VIRTUAL_KEY=gemini-your-virtual-key
MODEL_NAME=gemini-proQuick deployment with Docker
The following four steps will get you started and set up for your Kubernetes deployment.
Step 1: Environment setup
Create your environment configuration:
# Clone the repository
git clone https://github.com/maddigsys/falco-vanguard
cd falco-vanguard
# Copy environment template
cp env.example .env
# Edit configuration for your environment
vim .envDevelopment environment
Step 2: Configure your AI provider
Edit your .env file with your chosen AI provider:
# Slack Configuration
SLACK_BOT_TOKEN=xoxb-your-slack-bot-token
SLACK_CHANNEL_NAME=#security-alerts
# AI Provider (choose one)
PROVIDER_NAME=ollama # Default: local AI, no API keys needed
MODEL_NAME=llama3
# Alert Processing
MIN_PRIORITY=warning
IGNORE_OLDER=1
LOG_LEVEL=INFO
Step 3: Deploy the system
Start the complete system with Docker Compose:
# Start all services
docker-compose up -d
# Check service health
curl http://localhost:8080/health
# Access the web dashboard
open http://localhost:8080/dashboardYou'll see the live security dashboard with real-time alert processing:
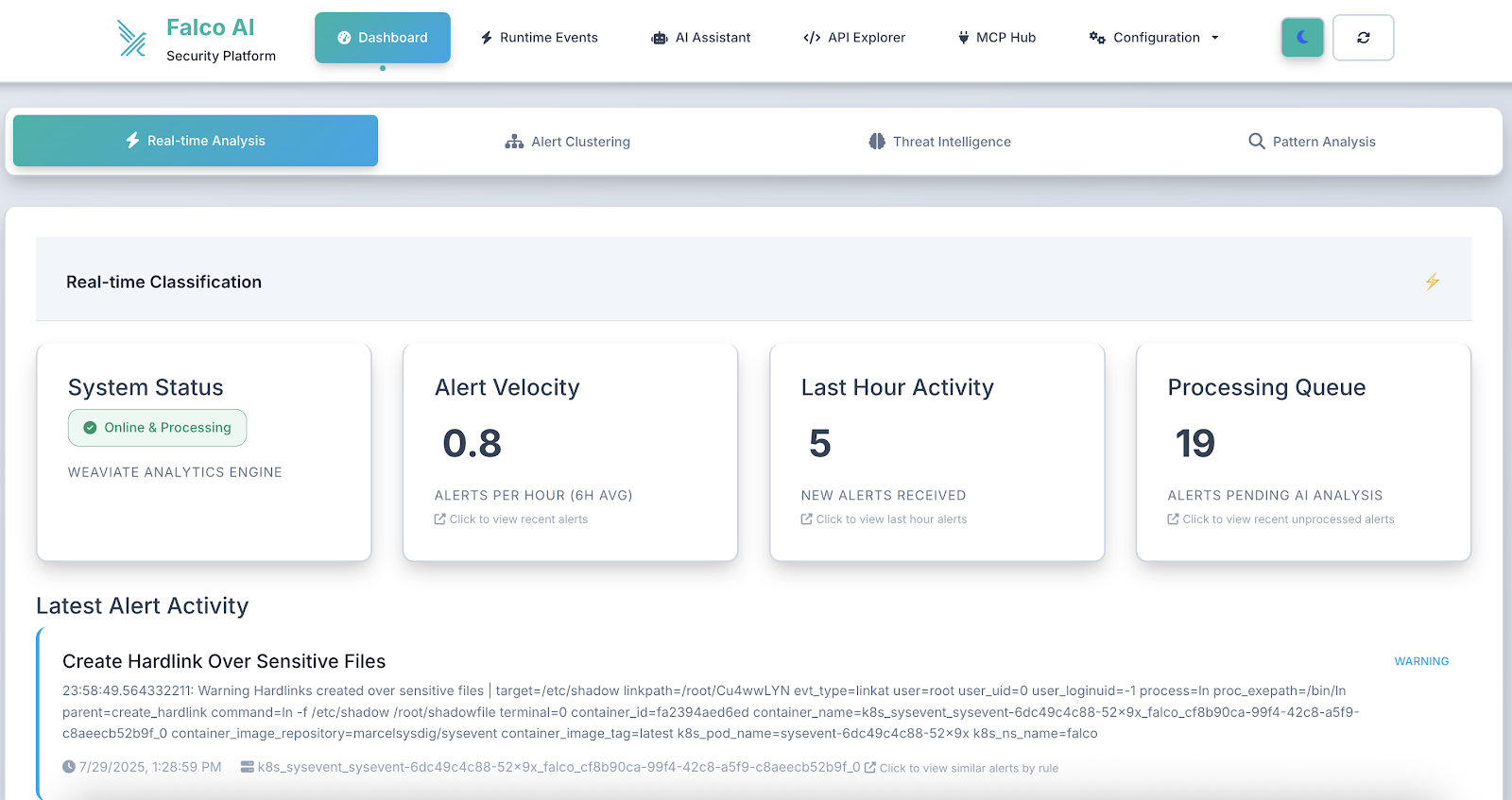
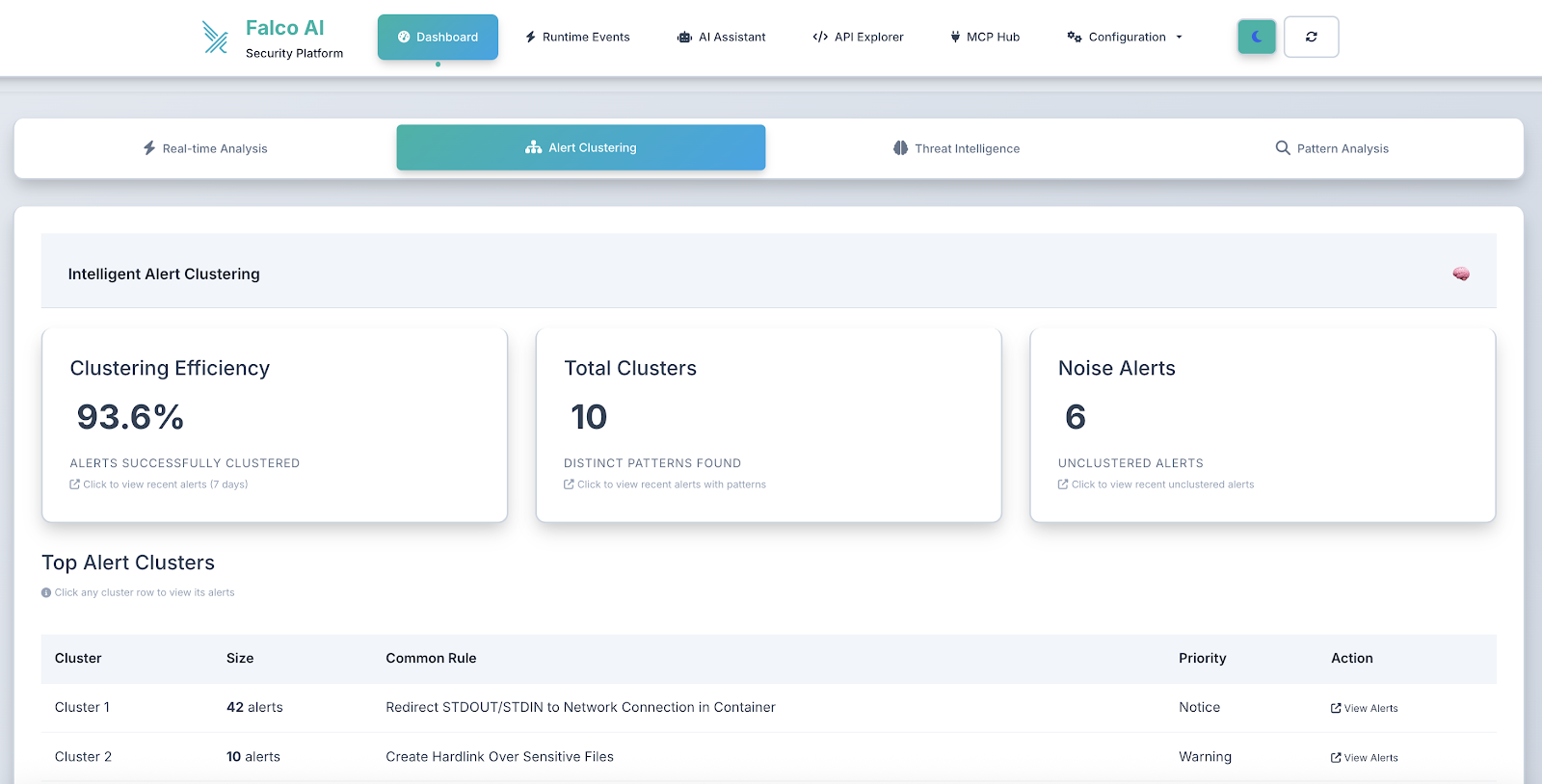
The dashboard immediately displays your security posture with key metrics and recent alerts, and offers easy access to an AI-enhanced chat assistant that can help you show configuration options through the top navigation bar.
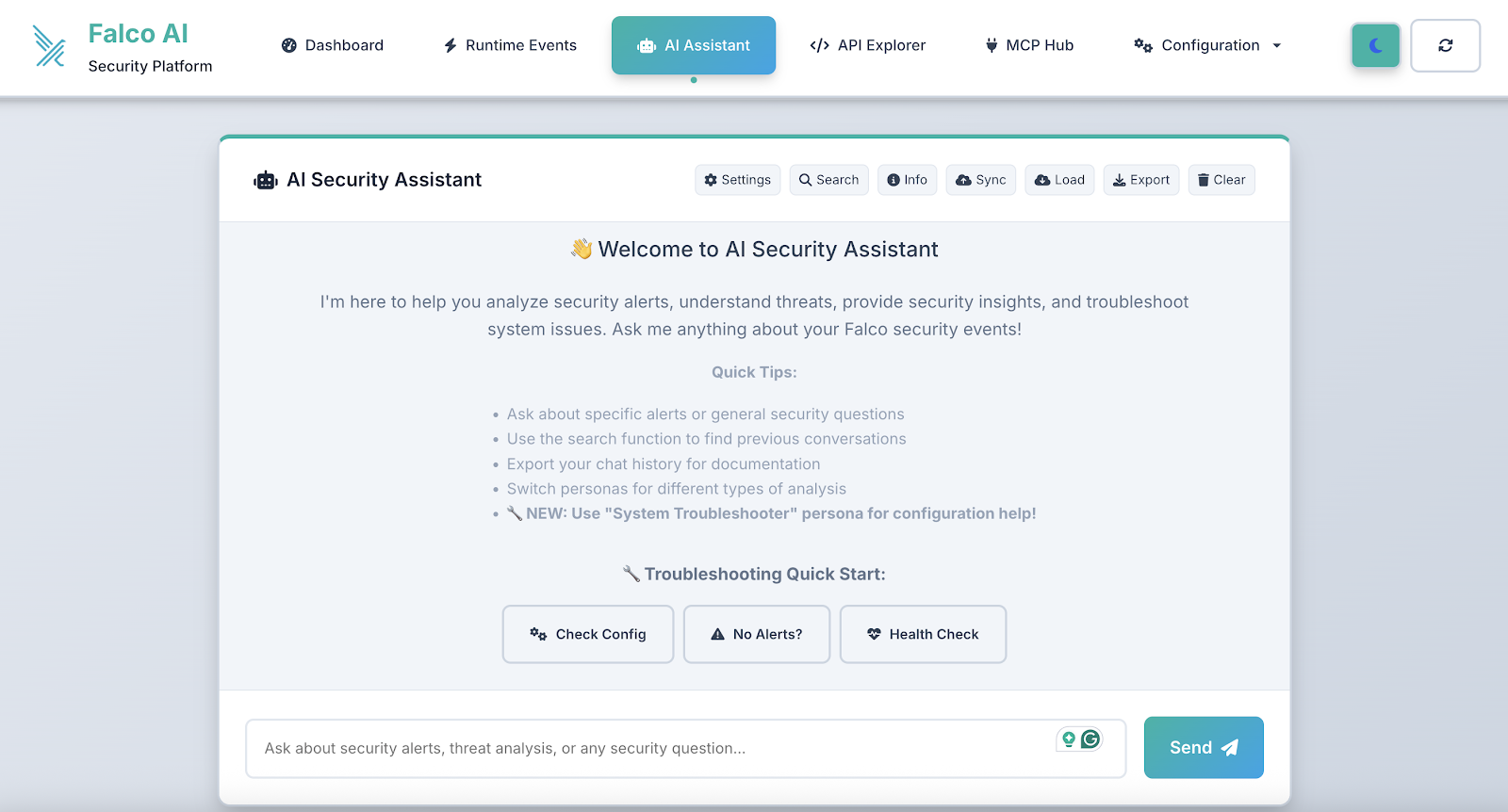
The dashboard provides real-time visibility into your security posture, with live alert statistics and an intuitive interface for managing security events.
Step 4: Configure Falco integration
Update your Falco configuration to send alerts to the webhook:
# Add to your falco.yaml
http_output:
enabled: true
url: "http://your-server:8080/falco-webhook"
user_agent: "falcosecurity/falco"
json_output: true
json_include_output_property: trueKubernetes deployment
Now that you have completed steps 1 through 4, it's time to deploy to Kubernetes. For development and production environments, deploy to Kubernetes using the provided manifests below:
Development environment
# Quick install with automated script
./k8s/install.sh dev
# Manual deployment
kubectl apply -k k8s/overlays/development/
# Access via port-forward
kubectl port-forward svc/dev-falco-vanguard 8080:8080 -n falco-vanguard-devProduction environment
# Production deployment with auto-scaling
./k8s/install.sh prod
# Manual deployment
kubectl apply -k k8s/overlays/production/
# Production features:
# - HPA auto-scaling (3-10 replicas)
# - Network policies for security
# - Resource limits and monitoring
# - Dedicated webhook serviceResource requirements
Keep in mind that there are resource requirements for development, production, and enterprise environments.
Environment
AI-powered security analysis
Now your system is ready to transform basic Falco alerts into comprehensive security intelligence.
Before: Raw Falco alert
{
"rule": "Terminal shell in container",
"priority": "warning",
"output": "A shell was used as the entrypoint/exec point into a container",
"output_fields": {
"container.name": "web-app",
"proc.cmdline": "/bin/bash",
"user.name": "root"
}
}
After: AI-enhanced analysis
Falco Vanguard generates structured analysis, including the following.
Security impact:
An interactive shell in a container may indicate unauthorized access, container escape attempts, or legitimate administrative activity that requires verification.
Next steps:
Immediately verify if this shell access was authorized, check authentication logs, and investigate recent container activities for signs of compromise.
Remediation steps:
Review container security policies, implement proper RBAC controls, and consider removing shell binaries from production containers.
Suggested commands:
kubectl describe pod <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> --previous
docker logs <container-id> --since 1hWeb dashboard features
The integrated web dashboard provides comprehensive alert management with a modern, intuitive interface:
Real-time security monitoring
The dashboard shows live security metrics, including:
- Total alerts: Complete count of processed security events
- Critical alerts: High-priority threats requiring immediate attention
- Recent activity: Last hour alert volume for trend analysis
- Alert status tracking: Unread, read, and dismissed alert counts
As alerts are processed and reviewed, the dashboard dynamically updates to reflect the current security posture, helping teams track their response progress.
Interactive alert management
- Priority-based filtering (critical, error, warning, notice)
- Time-range analysis (1h, 24h, 7d, 30d)
- Alert status management (unread, read, dismissed)
- Bulk operations for efficient alert processing
The system processes alerts in real time, with the dashboard updating automatically as new security events are detected and analyzed by the AI engine.
Advanced security analytics
- Trend visualization showing security patterns over time
- Alert correlation to identify related security events
- Performance metrics for AI analysis and response times
- Integration status monitoring for connected systems
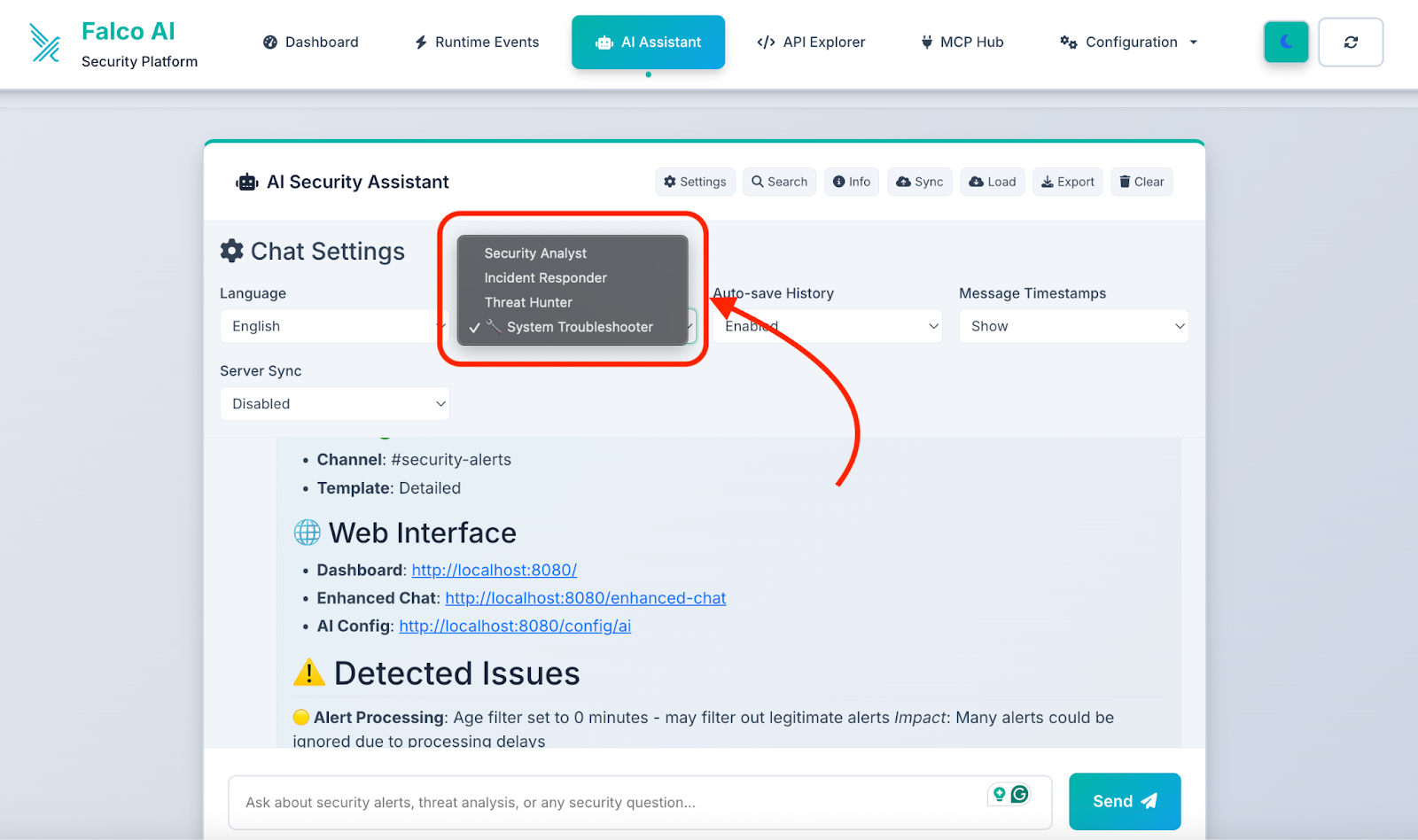
AI security chat
- Persona-based conversational structure
- Context-aware responses based on your alert data
- Trend analysis and security recommendations
- Custom queries about your security posture
Configuration management
- AI provider settings: Switch between OpenAI, Gemini, and Ollama
- Slack integration: Configure notifications and message templates
- Alert processing: Customize filtering and deduplication rules
- System monitoring: Real-time health checks and status
Advanced configuration
Multi-provider AI setup
Configure multiple AI providers for redundancy:
# Primary provider
PROVIDER_NAME=ollama
OLLAMA_MODEL_NAME=llama3
# Fallback providers (configured via web UI)
# OpenAI for high-priority alerts
# Gemini for batch analysisCustom security models
For enhanced cybersecurity analysis, deploy specialized models:
# Cybersecurity-optimized model
OLLAMA_MODEL_NAME=jimscard/whiterabbit-neo:latest
# Requires: 16GB RAM, specialized security trainingSlack message customization
The system supports rich Slack message formatting:
{
"template_style": "detailed",
"include_commands": true,
"thread_alerts": false,
"escalation_enabled": true
}
Testing your deployment
Send test alerts
Use the provided testing script to verify your setup:
# Send sample security alerts
./test-scripts/send-test-alert.shAfter sending test alerts, you'll see the dashboard update in real time:
The system processes each alert through the AI analysis pipeline, providing immediate feedback on security events with contextual analysis and recommended actions.
1# Test specific alert types
2curl -X POST http://localhost:8080/falco-webhook \
3 -H "Content-Type: application/json" \
4 -d '{
5 "rule": "Suspicious network activity",
6 "priority": "critical",
7 "output": "Outbound connection to known C2 server detected",
8 "output_fields": {
9 "fd.name": "malicious.example.com:443",
10 "proc.name": "curl"
11 }
12 }'
13Monitor system health
# Check application health
curl http://localhost:8080/health
# View processing logs
docker-compose logs -f falco-vanguard
# Monitor AI analysis performance
kubectl logs -f deployment/prod-falco-vanguard -n falco-vanguardProduction considerations
Security hardening
For production deployments:
- TLS termination: Use HTTPS for webhook endpoints
- Network policies: Implement Kubernetes network security
- RBAC controls: Limit service account permissions
- Secrets management: Use external secret stores
- Resource limits: Prevent resource exhaustion
Monitoring and observability
- Prometheus metrics: Built-in health and performance metrics
- Structured logging: JSON-formatted logs for analysis
- Alert correlation: Track alert processing pipeline
- Performance monitoring: AI inference timing and success rates
Scaling considerations
- Horizontal pod autoscaling: Auto-scale based on CPU/memory
- Database optimization: Configure retention and cleanup
- AI provider load balancing: Distribute requests across providers
- Webhook rate limiting: Handle high-volume alert scenarios
Best practices for implementation
Start with essential security controls
- Prioritize critical alerts: Focus on container escapes and privilege escalation.
- Use local AI first: Ollama provides privacy and reduces external dependencies.
- Implement gradual rollout: Test with non-production environments
Automate with infrastructure as code
- Kubernetes manifests: Version-controlled deployment configurations
- Environment-specific overlays: Separate dev/staging/production configs
- Automated deployment: CI/CD integration for updates and patches
Continuous improvement
- Monitor false positives: Fine-tune alert filtering and AI prompts
- Update AI models: Regular model updates for improved analysis
- Security feedback loop: Incorporate incident learnings into alert processing
Getting started
Ready to enhance your Falco deployment with AI-powered analysis? Here's your quick start path:
- Deploy locally: Use Docker Compose for initial testing
- Configure AI provider: Start with Ollama for simplicity
- Test with sample alerts: Verify AI analysis quality
- Deploy to Kubernetes: Scale for production workloads
- Integrate with Falco: Configure webhook delivery
- Monitor and tune: Optimize for your environment
The Falco Vanguard transforms security monitoring from reactive alerting to proactive threat intelligence, helping security teams respond faster and more effectively to runtime threats.
For more information and detailed examples, refer to the project documentation and deployment guides.
About the project
Falco Vanguard is an open source project designed to bridge the gap between raw security alerts and actionable threat intelligence. Built by security practitioners for security teams, it provides enterprise-grade capabilities with the flexibility of open-source deployment.
Key features:
- ✅ Multi-provider AI integration (OpenAI, Gemini, Ollama) using Portkey
- ✅ Real-time web dashboard with security analytics
- ✅ Kubernetes-native deployment with auto-scaling
- ✅ Rich Slack integration with actionable insights
- ✅ Privacy-focused local AI options
- ✅ Production-ready security hardening
Visit the GitHub repository to get started, contribute, or learn more about extending the system for your specific security needs.
Want to see more projects like this or have yours featured? Join the Sysdig Open Source Community today!

Miguel De Los Santos, the creator of this project, is a results-oriented technology professional with extensive experience in sales engineering, cybersecurity, cloud computing, and education. As a Senior Sales Engineer at Sysdig, he acts as a trusted advisor, guiding customers toward achieving their goals with cloud security solutions. His expertise includes understanding customer needs, showcasing product capabilities, and ensuring seamless adoption. Before Sysdig, he held sales engineering roles at VISO TRUST and F5, specializing in third-party cyber risk and global solutions architecture, respectively. Miguel is also passionate about education, serving as an Adjunct Professor at Hult International Business School, teaching FinTech, and as an Adjunct Instructor at Urban College of Boston for over 11 years, focusing on computer applications and technology. He holds a Master of Applied Computer Science from the Wentworth Institute of Technology and is a Certified Third-Party Risk Professional. His achievements include awards like the 2018 Force Multiplier and the 2016 President's Club. He is fluent in English and Spanish.