

Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2021年3月11日にJesus Ángel Samitierが投稿したブログ(https://sysdig.com/blog/getting-started-with-promql-includes-cheatsheet)を元に日本語に翻訳・再構成した内容となっております。
Prometheusの世界に初めて足を踏み入れた時に、すぐにPromQLを使いこなすのは難しいかもしれません。なぜならば、Prometheusは時系列データモデルでデータを保存するため、Prometheusサーバーでのクエリーは従来のSQLとは根本的に異なるからです。
Prometheusでデータがどのように管理されているかを理解することが、パフォーマンスの良いPromQLクエリーの書き方を学ぶ鍵となります。
この記事では、PromQLの基本を紹介していきたいと思います。また、PrometheusとPromQLをより深く理解するためのチートシートをダウンロードして入手してください。

時系列データベースの仕組み
時系列とは、タイムスタンプに関連付けられた値のストリームです。
すべての時系列は、以下のように、そのメトリクス名とラベルで識別されます。mongodb_up{}またはkube_node_labels{cluster="aws-01", label_kubernetes_io_role="master"}上記の例では、メトリクス名(kube_node_labels)とラベル(clusterとlabel_kubernetes_io_role)が表示されています。通常はこのようにメトリクスとラベルを参照しますが、実はメトリクスの名前もラベルなのです。上記のクエリーは次のようにも書けます。{__name__ = "kube_node_labels", cluster="aws-01", label_kubernetes_io_role="master"}Prometheusには4種類のメトリクスがあります:
- ゲージは上がったり下がったりする任意の値です。例えば、mongodb_upは、エクスポーターがMongoDBインスタンスに接続しているかどうかを教えてくれます。
- カウンターは、エクスポーターの最初からの積算値を表し、通常は_totalという接尾辞を持ちます。例えば、http_requests_totalのようになります。
- ヒストグラムは、リクエストの継続時間やレスポンスのサイズなどの観測値をサンプリングして、 設定可能なバケツでカウントします。
- サマリーは、ヒストグラムとして動作し、設定可能な数量を計算します。
PromQLデータ選択を始める
PromQLでのデータの選択は、データを取得したいメトリクスを指定するだけで簡単にできます。この例では、http_requests_totalというメトリクスを使用します。
ホスト10.2.0.4における/apiパスのリクエスト数を知りたいと想像してみてください。そのためには、メトリクスからホストとパスのラベルを使用します。
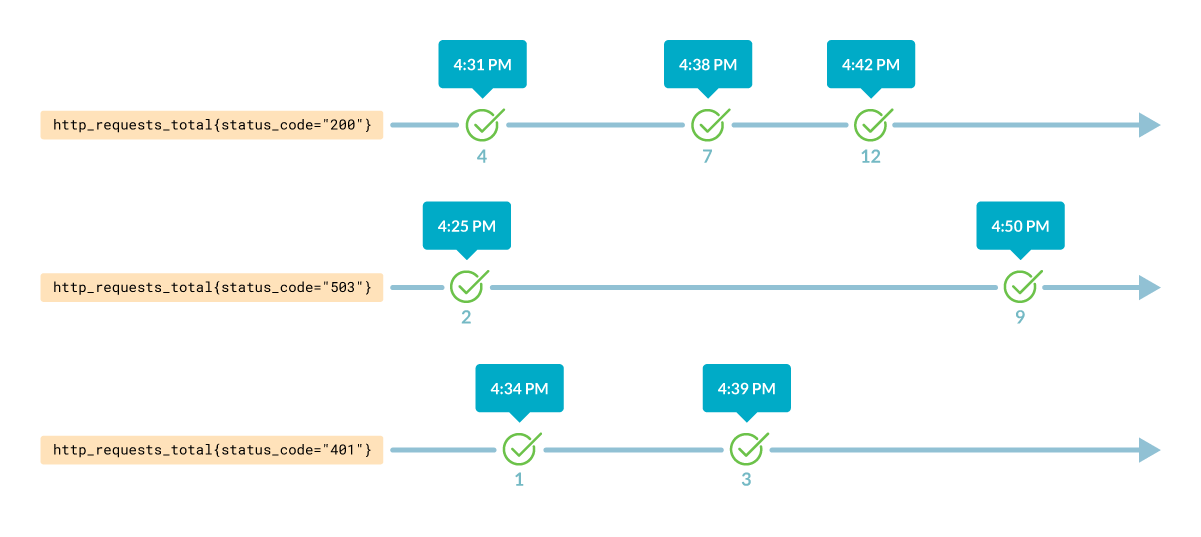
次のようなPromQLクエリーを実行することができます:http_requests_total{host="10.2.0.4", path="/api"}次のようなデータが返されます。
名前ホストパスステータスコード値http_requests_total10.2.0.4/api20098http_requests_total10.2.0.4/api50320http_requests_total10.2.0.4/api4011
このテーブルの各行は、利用可能な最後の値を持つ系列を表しています。http_requests_totalには、最後にカウンターを再起動してからのリクエスト数が含まれているため、98件のリクエストが成功したことがわかります。
これはインスタント・ベクトルと呼ばれ、クエリーで指定された瞬間の各系列の最も古い値を表しています。サンプルはランダムな時間に採取されるので、Prometheusはサンプルを選択するために近似値を作らなければなりません。時刻が指定されていない場合は、最後に得られた値が返されます。
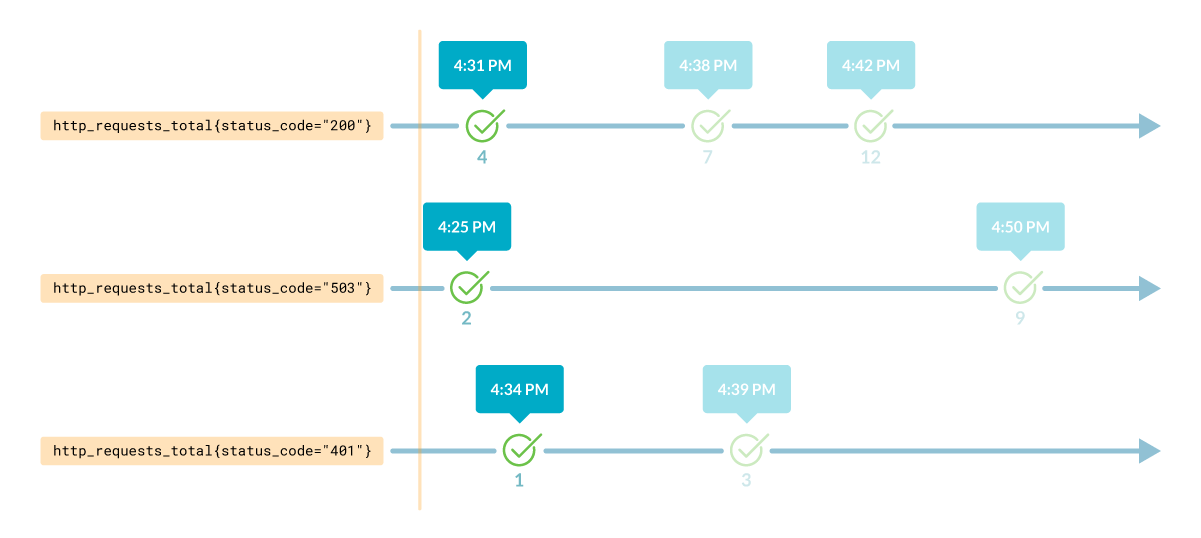
さらに、別の瞬間(例えば、1日前)のインスタント・ベクトルを取得することもできます。
そのためには、次のようにオフセットを追加するだけでよいのです:
http_requests_total{host="10.2.0.4", path="/api", status_code="200"} offset 1d
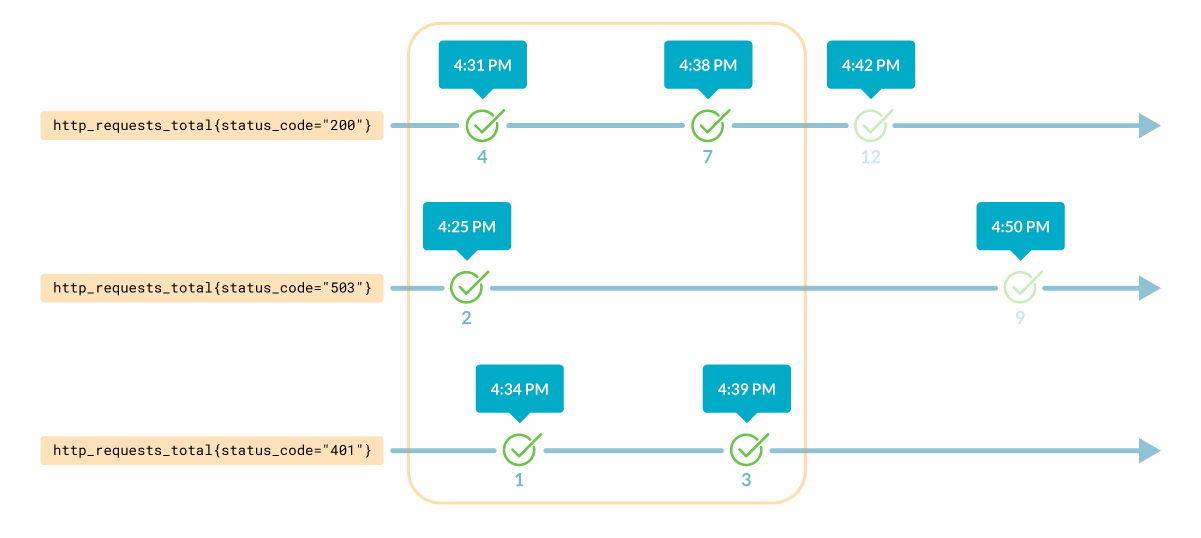
タイムスタンプの範囲内でメトリクスの結果を得るには、それを括弧で囲んで示す必要があります。
http_requests_total{host="10.2.0.4", path="/api"}[10m]
これは次のようなものを返します:
名前ホストパスステータスコード値http_requests_total10.2.0.4/api200641309@1614690905.515
641314@1614690965.515
641319@1614691025.502
http_requests_total10.2.0.5/api200641319 @1614690936.628
641324 @1614690996.628
641329 @1614691056.628
http_requests_total10.2.0.2/api401368736 @1614690901.371
368737 @1614690961.372
368738 @1614691021.372
このクエリーは、各時系列に対して複数の値を返します。これは、時間範囲内のデータを求めたためです。したがって、すべての値はタイムスタンプと関連付けられています。
これはレンジベクトルと呼ばれ、タイムスタンプの範囲内にあるすべての時系列の値を表しています。
PromQLの集計と演算子を使いこなす
ご覧のように、PromQLのセレクターはメトリクスデータの取得に役立ちます。しかし、より洗練された結果を得たい場合はどうすればよいでしょうか。
例えば、クラスターラベル付きのメトリクスnode_cpu_coresがあったとします。例えば、特定のラベルで集計して結果を合計することができます。
sum by (cluster) (node_cpu_cores)
この場合、次のような結果が得られます:
clustervaluefoo100bar50
この単純なクエリーでは、cluster_fooには100個のCPUコアがあり、cluster_barには50個のCPUコアがあることがわかります。
さらに、PromQLのクエリーでは、算術演算子を使用することができます。例えば、空きメモリの量をバイト単位で返すメトリクスnode_memory_MemFree_bytesを使用して、div演算子を使用してメガバイト単位の値を得ることができます。
node_memory_MemFree_bytes / (1024 * 1024)
前述のメトリクスと、ノードで利用可能な総メモリ量を返すnode_memory_MemTotal_bytesを比較することで、利用可能な空きメモリの割合を得ることもできます。
(node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100
また、空きメモリが5%未満のノードがあった場合にアラートを作成するためにも利用できます。
(node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100 < 5
PromQL関数を使う
PromQLには、さらに洗練された結果を得るために使用できる膨大な関数のコレクションがあります。前述の例では、topk関数を使用して、どの2つのノードがより高い空きメモリ率を持っているかを特定することができます。
topk(2, (node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100)
Prometheusは、過去の情報だけでなく、未来の情報も提供してくれます。predict_linear 関数は、与えられた秒数の間に時系列がどこになるかを予測します。この関数を使って、休日用の完璧なハムを作ったことを覚えているでしょうか。
次の24時間以内に利用可能なディスクの空き容量を知りたいとします。predict_linear関数を先週のnode_filesystem_free_bytesメトリクスの結果に適用すると、利用可能なディスクの空き容量が返されます。これにより、今後24時間以内の空きディスク容量をギガバイト単位で予測することができます。
predict_linear(node_filesystem_free_bytes[1w], 3600 * 24) / (1024 * 1024 * 1024) < 100
Prometheusのカウンターを扱うとき、rate関数はとても便利です。これは、カウンタの1秒ごとの増加を計算し、リセットやエッジでの推定を可能にして、より良い結果をもたらします。
もし、過去 10 分間にリクエストを受け取っていない場合に、アラートを作成する必要があるとしたらどうでしょう。タイムスタンプの範囲内でカウンタがリセットされると、結果が正確でなくなるので、単に http_requests_total メトリクスを使用することはできません。
http_requests_total[10m]
名前ホストパスステータスコード値http_requests_total10.2.0.4/api200100@1614690905.515
300@1614690965.515
50@1614691025.502
上記の例では、カウンターがリセットされたため、300から50までのマイナスの値が出ています。このメトリクスだけでは十分ではありません。ここで、rate関数の出番です。リセットを考慮しながら、あたかもこのように結果が固定されていきます。
名前ホストパスステータスコード値http_requests_total10.2.0.4/api200100@1614690905.515
300@1614690965.515
350@1614691025.502
rate(http_requests_total[10m])名前
ホスト
パス
ステータスコード値http_requests_total10.2.0.4/api2000.83
リセットの有無にかかわらず、過去10分間の平均で1秒あたり0.83回のリクエストがありました。ここで、必要なアラートを設定します。
rate(http_requests_total[10m]) = 0
次のステップ
この記事では、Prometheusがどのようにデータを保存しているか、そしてPromQLの例を使ってデータの選択と集計を始める方法を学びました。
PromQL チートシートをダウンロードして、PromQLの演算子、集計、関数の詳細や例を学ぶことができます。また、Prometheus playgroundですべての例を試すことができます。
Sysdig MonitorはPrometheusと完全な互換性がありますので、Sysdig Monitor 30日間無料トライアルもお試しいただけます。数分で使い始めることができます!