

Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2022年11月9日にVictor Hernandoが投稿したブログ(https://sysdig.com/blog/monitor-etcd/)を元に日本語に翻訳・再構成した内容となっております。
Etcdは、Kubernetesクラスターに関連するすべてのデータのバックエンドストアです。Kubernetesインフラストラクチャーにおける重要なコンポーネントであることは間違いありません。Kubernetesのetcdの監視に失敗すると、おそらく問題の予防にも失敗するため、etcdを適切に監視することは極めて重要です。その場合、深刻なトラブルに巻き込まれる可能性があります。

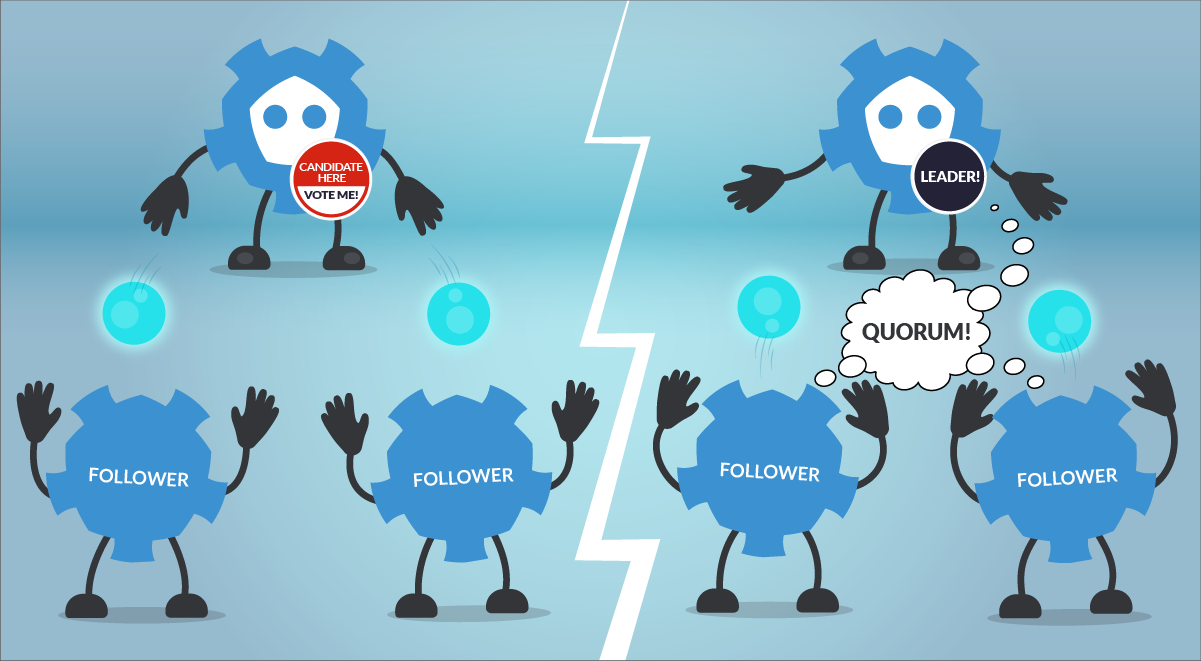
左側は、あるetcdメンバーがリーダー候補として宣言し、他のメンバーに提案を送っているところです。右側は、他のetcdメンバーが投票を確認・提示し、リーダーが選出され、定数に達している様子です。
etcdのquorumがなくなり、etcdが結果的にクラスターでフェイルすると、Kubernetesが現在の状態に変更を加えることができなくなります。新しいPodがスケジュールされなくなるなど、さまざまな問題が発生します。etcdノード間の大きなレイテンシー、ディスクパフォーマンスの問題、または高いスループットは、etcdの可用性の問題の一般的な根本原因のいくつかです。
etcdをどのように監視するかは、Kubernetesとクラウドネイティブの旅を続けている企業にとってホットなトピックです。幸いなことに、Kubernetesのetcdは、etcdのメトリクスをすぐに提供できるようにインストルメント化されています。DIYのPrometheusインスタンスまたはPrometheusマネージドサービスのどちらからでも、etcdメトリクスをスクレイピングして、Kubernetesクラスターの最も重要なコンポーネントの1つを制御することができます。
もしあなたがetcdを監視する方法、どのメトリクスをチェックすべきか、その意味は何か、そしてKubernetes etcdの問題を防御する方法を学びたいのなら…。
あなたは正しい場所にいます👌。読み進めてください
この記事では、以下のトピックを取り上げます:
- etcdとは?
- etcdを監視する方法
- etcdを監視する。どのメトリクスをチェックするのか?
- まとめ
etcdとは?
etcdは分散型キーバリューオープンソースデータベースで、分散システムやマシンのクラスターからアクセスする必要があるデータを保存するための信頼性の高い方法を提供します。Kubernetesについて語るとき、etcdはクラスターの要であると言えます。Kubernetesはetcdの分散データベースを活用して、REST APIオブジェクトを(/registryディレクトリキーの下に)保存しています。Pods、Service、Ingressなど、あらゆるものが追跡され、key-value形式でetcdに保存されます。
では、Kubernetesのetcdがダウンしたらどうなるのでしょうか?
etcd quorumが失われ、新しいリーダーを選出できない場合、現在のPodとワークロードはKubernetesクラスターで稼働し続けることになります。しかし、新たな変更はできず、新しいPodをスケジュールすることもできません。
リーダーの選出と「コンセンサス」に関して、etcdはRAFTアルゴリズムを使用しています。これは、分散された耐障害性のあるクラスターノードの集合上で収束を達成するための方法です。基本的に、RAFTがetcdのリーダー選出にどのように役立つのかについて知っておく必要があるのは:
ノードのステータスが以下のいずれかになります:
- Follower
- Candidate
- Leader
選挙プロセスはどのように機能するのでしょうか?
- Followerは、現在のLeaderを見つけられない場合、Candidateとなります。
- 投票システムにより、Candidateの中から新しいLeaderが選出されます。
- レジストリ値の更新(コミット)は常にLeaderを経由して行われます。しかし、クライアントはどのノードがLeaderであるかを知りません。Followerが合意を必要とする要求を受け取った場合、その要求を自動的にLeaderに転送します。
- Leaderが大多数のFollowerからackを受け取ると、新しい値が「コミット」されたとみなされます。
- クラスターはほとんどのノードが生存している限り存続します。
おそらくetcdの最も顕著な特徴は以下の通りです:
- REST ライクな HTTP 呼び出しで簡単にサービスにアクセスできること。
- クラスターリーダを自動的に選出し、必要に応じてその役割を切り替えるフォールバック機構を提供するmaster-masterプロトコル。
分散システムやKubernetesクラスターのデータを保存するためにetcdを実行する場合、奇数ノードを使用することが推奨されます。Quorumは、クラスターの状態の更新に同意するために、クラスター内のノードの過半数を必要とします。ノード数がnのクラスターでは、クラスターを構成するのに必要なクォーラムは(n/2)+1です。例えば
- 3ノード・クラスターの場合、Quorumは2ノードで達成されます。(故障許容度1ノード)
- 4ノードクラスターの場合、Quorumは3ノードで達成されます。(故障許容度1ノード)
- 5ノードクラスターの場合、Quorumは3ノードで達成されます。(障害許容度2ノード)
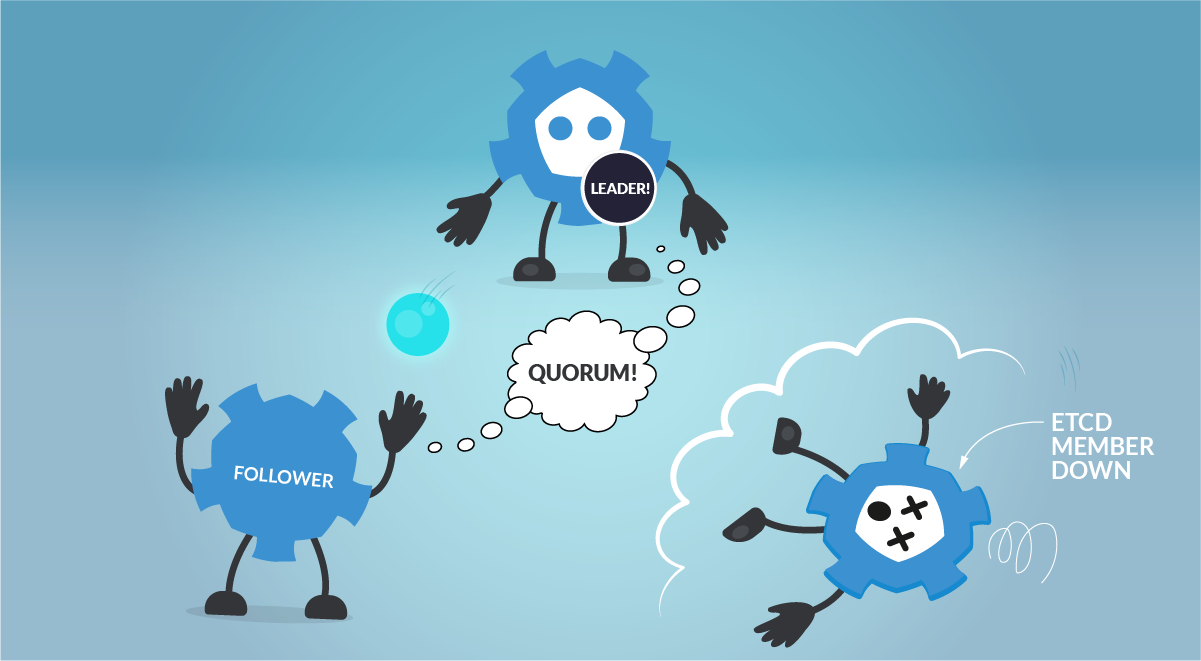
etcdメンバーの1つがダウンしています。3ノードのetcdクラスターでは、Quorumは2ノードで達成されるため、etcdクラスターは正常に動作し続けることができます。
奇数サイズのクラスターは、偶数サイズのクラスターと同じ数の障害を許容しますが、ノード数は少なくなります。さらに、ネットワーク・パーティションが発生した場合、奇数ノードは常に多数派のパーティションが存在することを保証し、恐ろしいスプリットブレイン・シナリオを回避することができます。こうすることで、ネットワーク・パーティションが解消されても、etcdクラスターは稼働し続け、真実の源となることができるのです。
最後に、 etcdctl CLIツールを使ってetcdを操作する方法を見てみましょう。etcdのメンバーの健康状態についての情報を得るのに便利です。
$ ETCDCTL_API=3 etcdctl \
--endpoints 192.168.119.30:2379,192.168.119.31:2379,192.168.119.32:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
endpoint status --write-out=table
etcdctlツールを使えば、etcdのenpointの状態を簡単に確認することができます。
また、etcdのバックエンドで直接データを参照することもできます:
$ ETCDCTL_API=3 etcdctl \
--endpoints 192.168.119.30:2379,192.168.119.31:2379,192.168.119.32:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
get / --prefix --keys-only
/registry/apiextensions.k8s.io/customresourcedefinitions/apiservers.operator.tigera.io
/registry/apiextensions.k8s.io/customresourcedefinitions/authorizationpolicies.security.istio.io
/registry/apiextensions.k8s.io/customresourcedefinitions/bgpconfigurations.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/bgppeers.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/blockaffinities.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/caliconodestatuses.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/clusterinformations.crd.projectcalico.org
/registry/apiextensions.k8s.io/customresourcedefinitions/destinationrules.networking.istio.io
/registry/apiextensions.k8s.io/customresourcedefinitions/envoyfilters.networking.istio.io
/registry/apiextensions.k8s.io/customresourcedefinitions/felixconfigurations.crd.projectcalico.org
(output truncated)etcdを監視する方法
前のセクションで述べたように、etcdはインストルメント化され、そのメトリクスエンドポイントを公開・提供しており、すべてのマスターホストでアクセス可能です。ユーザーは、スクリプトや追加のエクスポーターを必要とせずに、このエンドポイントから簡単にメトリクスを取得することができます。メトリクスエンドポイントをcurlするだけで、Kubernetesのetcdメトリクスに関連するすべてのデータを取得することができます。
しかし、このエンドポイントはセキュリティで保護されています。etcdクライアントリクエストの公式ポート、あなたが/メトリクスエンドポイントにアクセスするために必要なものと同じものは、2379です。つまり、etcd /metricsエンドポイントからメトリクスをスクレイピングしたい場合、Kubernetes etcdクライアントポートにアクセスし、etcdクライアント証明書を所有する必要があるのです。
Kubernetes etcdのPod yaml定義の1つ、具体的にはKubernetes etcdが使用するエンドポイントポートを確認してみましょう。
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.119.30:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.168.119.30:2380
- --initial-cluster=k8s-control-1.lab.example.com=https://192.168.119.30:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.119.30:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.119.30:2380
- --name=k8s-control-1.lab.example.com
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.k8s.io/etcd:3.5.4-0ここで、/metricsエンドポイントに到達するために使用するエンドポイントを特定する –listen-client-urls パラメータと、この保護されたエンドポイントにアクセスするために必要な –cert-file と –key-file 証明書を確認することができます。
エンドポイントに手動でアクセスする
これらの証明書なしで/metricsエンドポイントにアクセスしようとすると、すぐにエンドポイントに到達できないことに気づくでしょう。
$ curl http://192.168.119.30:2379/metrics
curl: (52) Empty reply from server
$ curl https://192.168.119.30:2379/metrics
curl: (60) SSL certificate problem: unable to get local issuer certificate
More details here: https://curl.haxx.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the web page mentioned above.では、etcdからメトリクスを取得するために必要なものは何でしょうか?
それは簡単で、マスターノードからetcdの証明書を取得し、Kubernetesのetcdエンドポイントをcurlするのです。
Note: 信頼されるためには、etcd CA certificate (ca.crt) を使うか、-k を使って検証をバイパスする必要があります。
$ curl --cacert etcd_certificates/ca.crt --cert etcd_certificates/server.crt --key etcd_certificates/server.key https://192.168.119.30:2379/metrics
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1
# HELP etcd_debugging_disk_backend_commit_rebalance_duration_seconds The latency distributions of commit.rebalance called by bboltdb backend.
# TYPE etcd_debugging_disk_backend_commit_rebalance_duration_seconds histogram
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.001"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.002"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.004"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.008"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.016"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.032"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.064"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.128"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.256"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.512"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="1.024"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="2.048"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="4.096"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="8.192"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="+Inf"} 4896
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_sum 0.0042786149999999995
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_count 4896
# HELP etcd_debugging_disk_backend_commit_spill_duration_seconds The latency distributions of commit.spill called by bboltdb backend.
(output truncated)etcdメトリクスをスクレイピングするPrometheusの設定方法
Kubernetesのetcdメトリクスエンドポイントにアクセスでき、etcdメトリクスを手動で取得できることを確認したら、次はPrometheusインスタンス、またはマネージドPrometheusサービスをetcdメトリクスをスクラップするように設定しましょう。
まず、監視ネームスペースに新しいシークレットを作成する必要があります。このシークレットは、etcdのメトリクスエンドポイントからメトリクスをスクレイピングするために必要なetcd証明書(前のセクションで使用したものと同じ)をマウントするものです。作成したシークレットを使用してprometheus-serverDeployment にパッチを当てます。
免責事項:etcdはあらゆるKubernetesクラスターの中核となるものです。証明書の扱いに注意しないと、クラスター全体が公開され、ターゲットにされる可能性があります。
$ kubectl create secret generic etcd-ca --from-file=etcd_certificates/server.crt --from-file=etcd_certificates/server.key -n monitoring
$ kubectl patch deployment prometheus-server -n monitoring -p '{"spec":{"template":{"spec":{"volumes":[{"name":"etcd-ca","secret":{"defaultMode":420,"secretName":"etcd-ca"}}]}}}}'
$ kubectl patch deployment prometheus-server -n monitoring -p '{"spec":{"template":{"spec":{"containers":[{"name":"prometheus-server","volumeMounts":[{"mountPath":"/opt/prometheus/secrets","name":"etcd-ca"}]}]}}}}'すでにDIYのPrometheusインスタンスやマネージドPrometheusサービスを持っていると仮定して、現在のprometheus-server ConfigMapを取得し、etcdメトリクス用に新しいscrape_configを追加する必要があります。 scrape_configs セクションの下にetcdのジョブを追加します。
$ kubectl get cm prometheus-server -n monitoring -o yaml > prometheus-server.yaml
$ vi prometheus-server.yaml
scrape_configs:
…
- job_name: etcd
scheme: https
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
separator: '/'
regex: 'kube-system/etcd.+'
- source_labels:
- __address__
action: replace
target_label: __address__
regex: (.+?)(\\:\\d)?
replacement: $1:2379
tls_config:
insecure_skip_verify: true
cert_file: /opt/prometheus/secrets/server.crt
key_file: /opt/prometheus/secrets/server.keyConfigMapをetcdエンドポイントを含む新しいものに置き換え、PrometheusのPodを再作成してこの新しい設定を適用します。
$ kubectl replace -f prometheus-server.yaml -n monitoring
$ kubectl delete pod prometheus-server-5df7b6d9bb-m2d27 -n monitoring
これで、PrometheusサーバーからスクレイピングされたKubernetesのetcdメトリクスを確認し、クエリを実行できるようになりました。
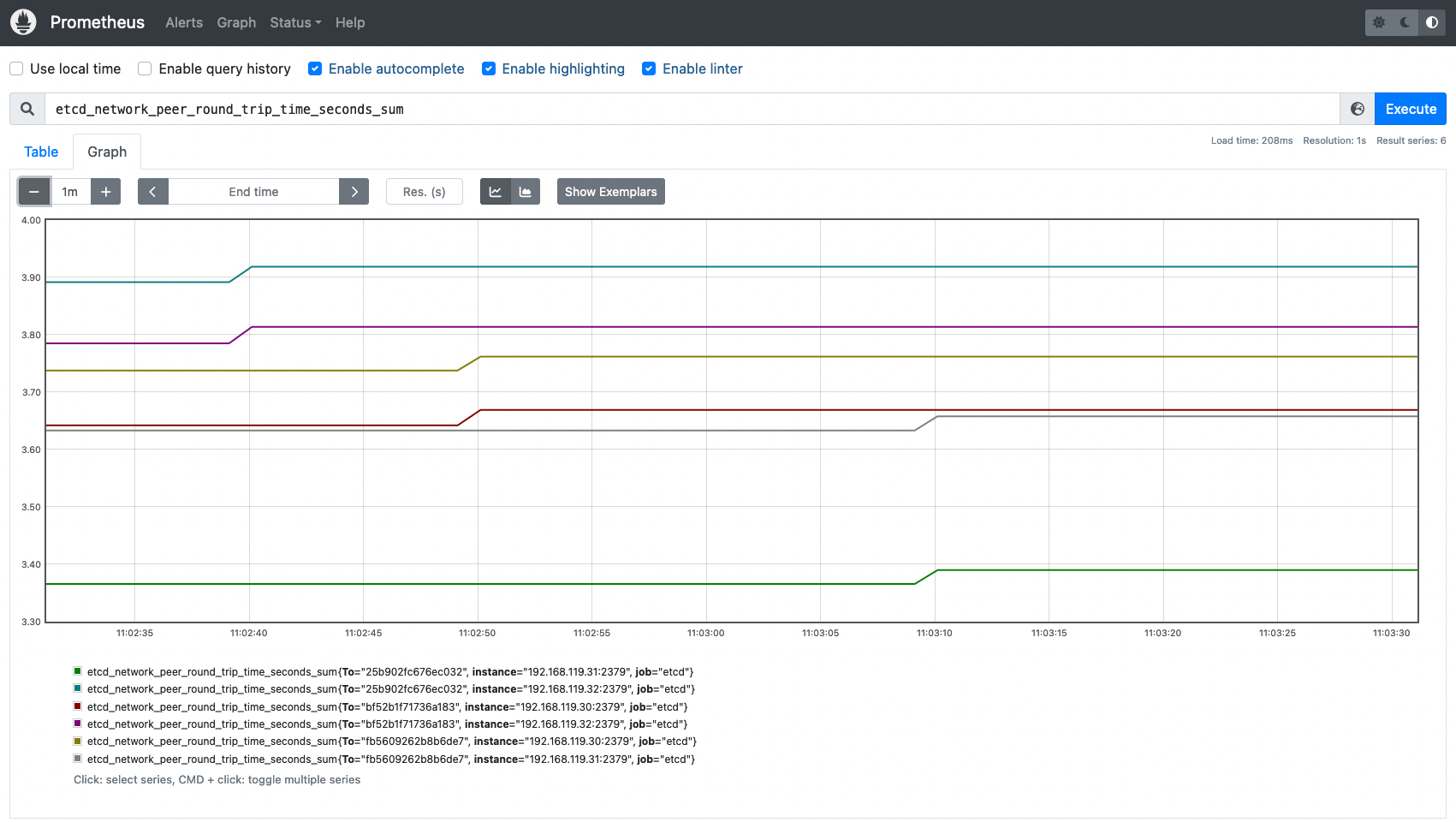
etcd_network_peer_round_trip_time_secondsメトリクスは、etcdメンバー間のレイテンシーを測定します。
etcdの監視:どのメトリクスを確認すればいいのか?
それでは、Kubernetes環境で監視すべき最も重要なetcdメトリクスを紹介して行きます。
免責事項:etcdのメトリクスは、Kubernetesのバージョンによって異なる場合があります。ここでは、Kubernetes 1.25とetcd 3.25を使用しました。etcdで利用できる最新のメトリクスは、etcdの公式ドキュメントで確認することができます。
etcdサーバーのメトリクス
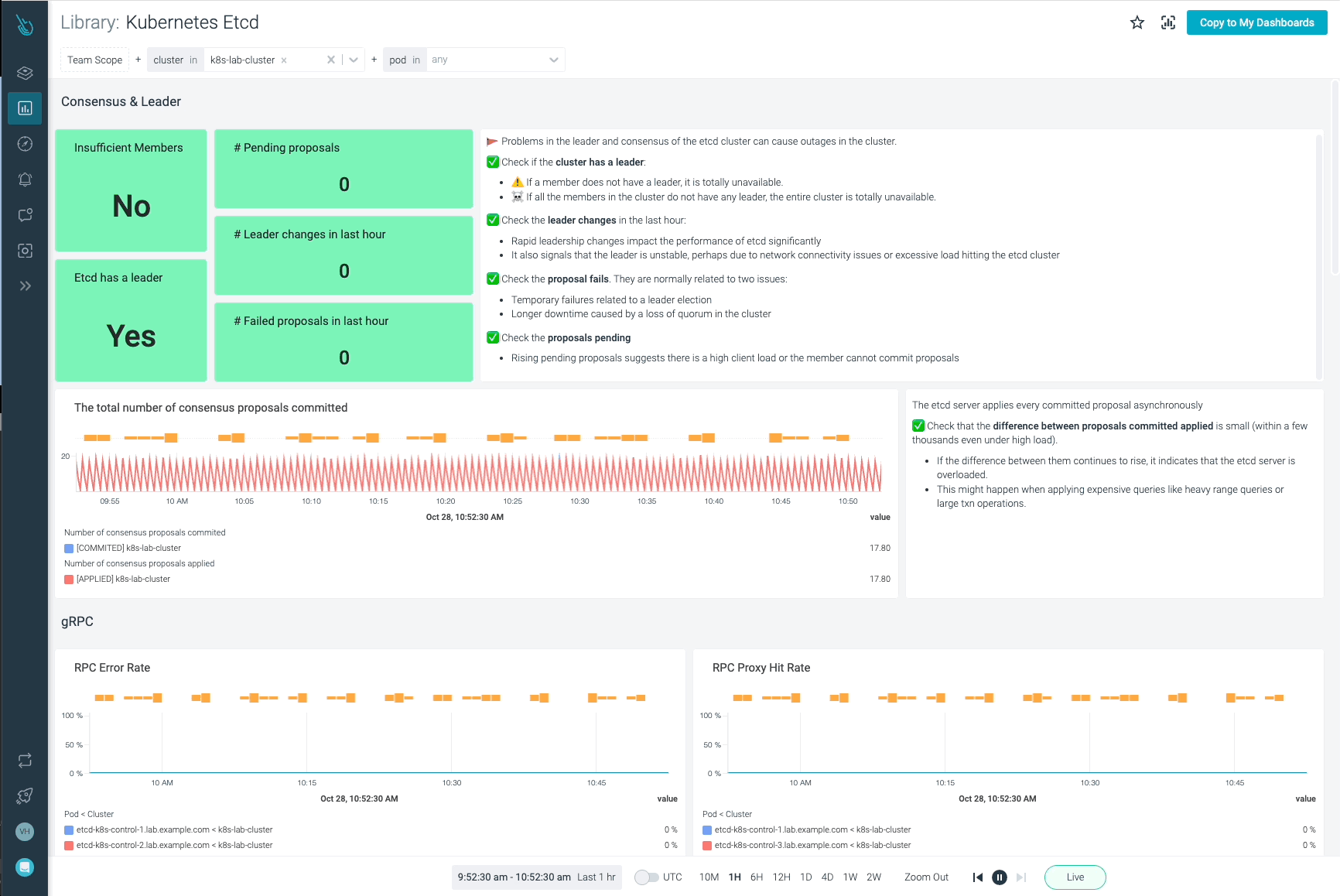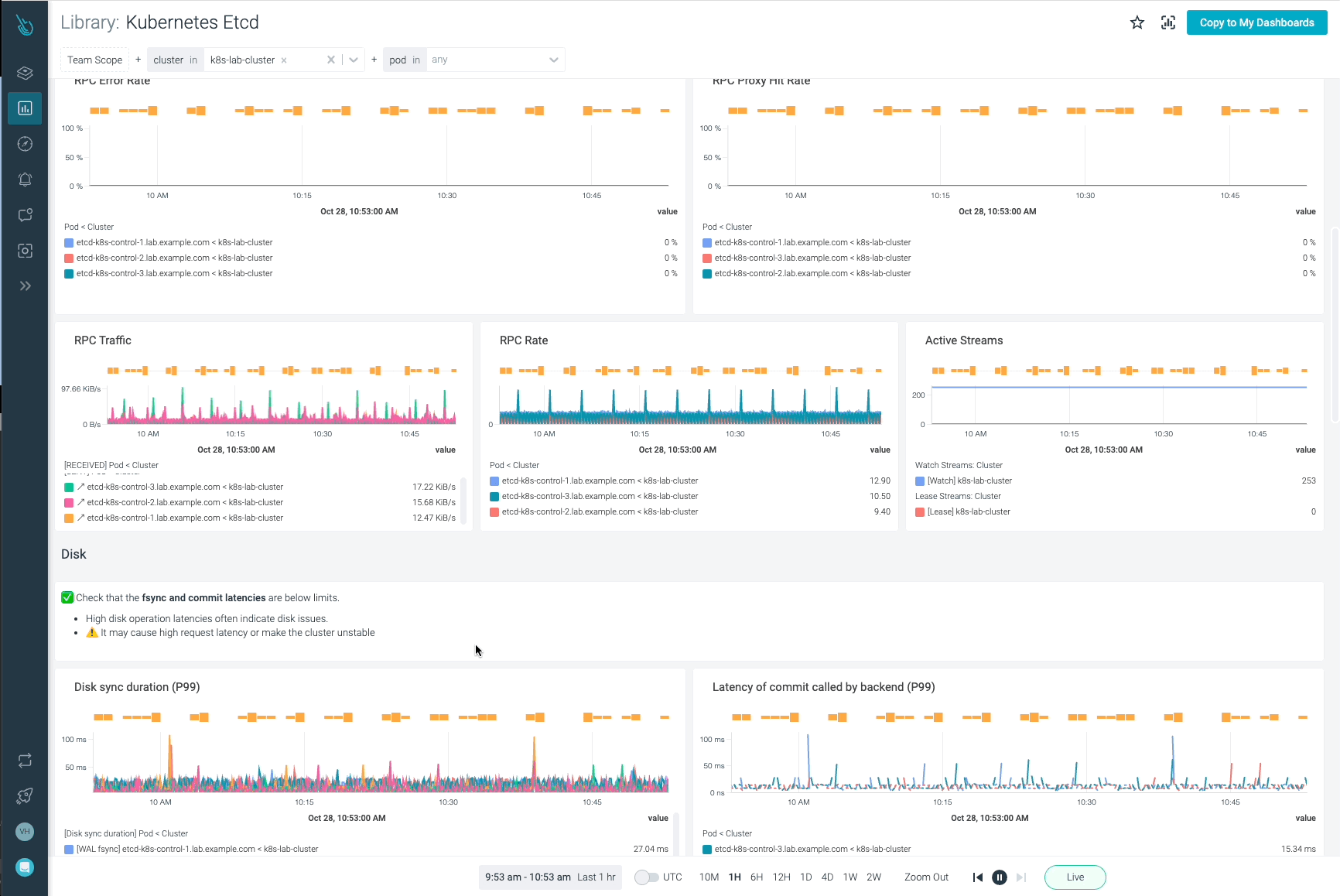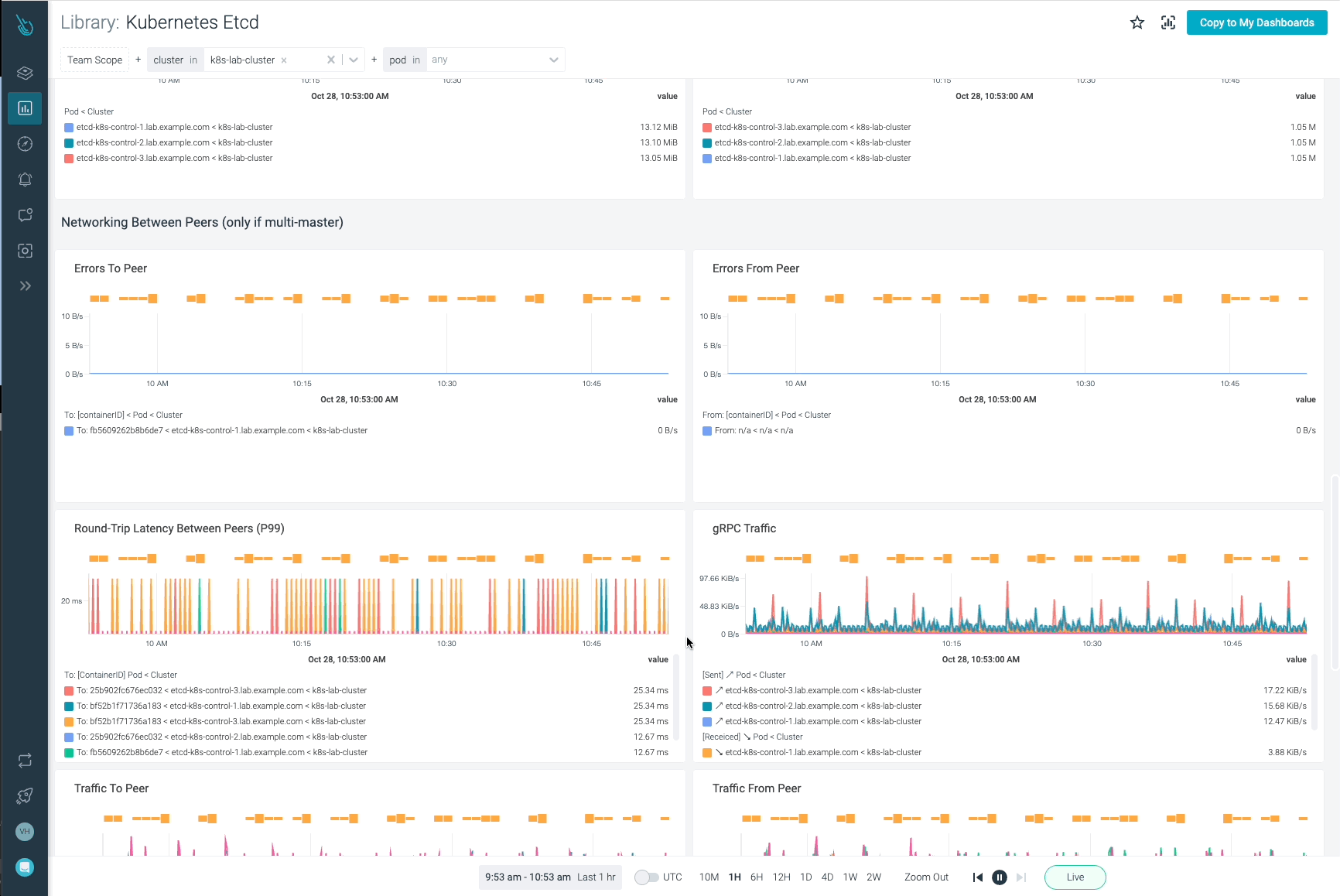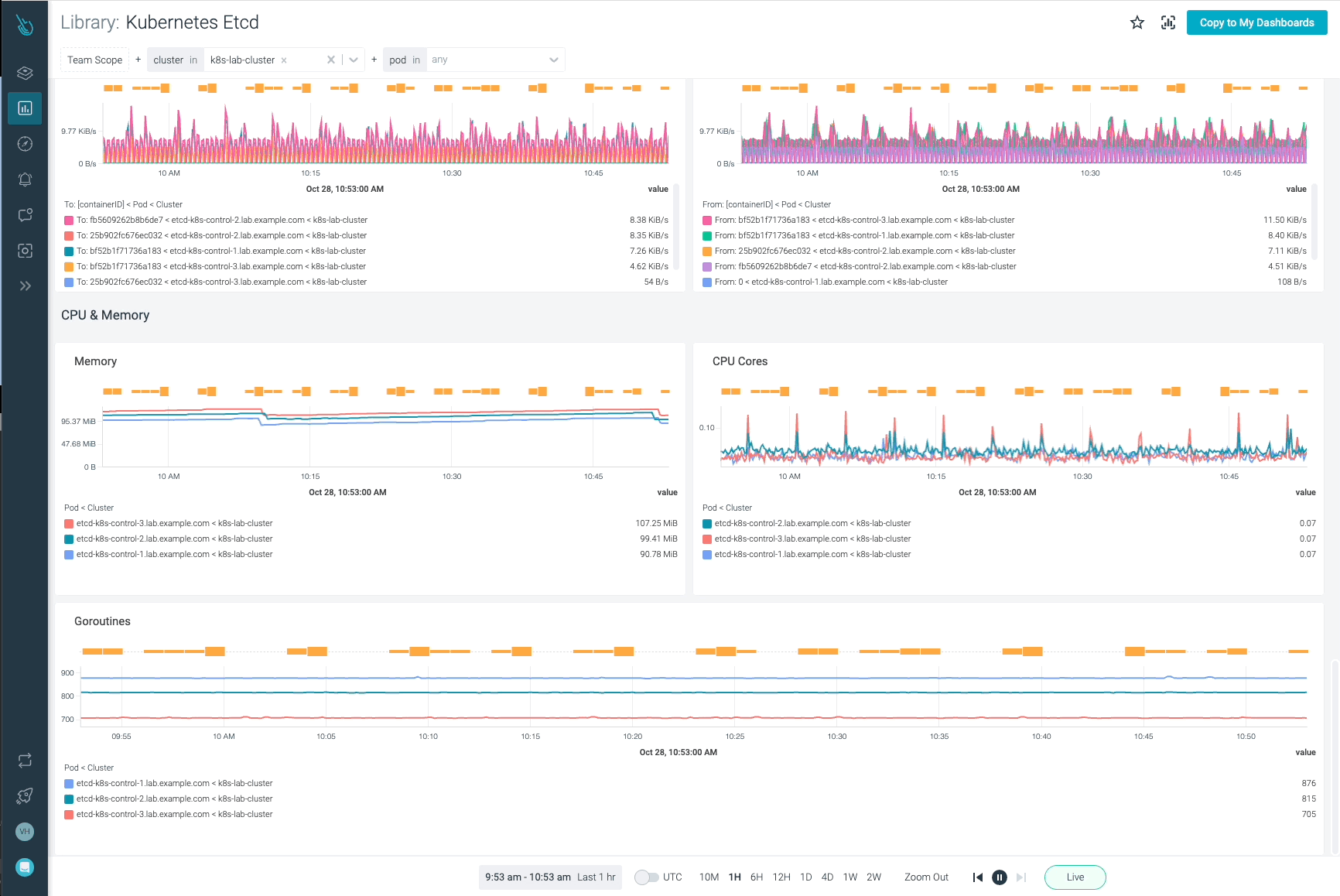
次に、主要なetcdサーバーのメトリクスをまとめます。これにより、etcdクラスターの可用性を確認することができます。
etcd node availability:クラスターについて話すとき、何らかの理由でノードが突然ダウンすることがあります。そのため、クラスターを構成するノードの可用性を監視することは、常に良いアイデアです。以下のようなPromQLを実行するだけで、クラスター内でアクティブなノードの数をカウントできます。
count(etcd_cluster_version)
etcd_server_has_leader: このメトリクスは、etcdノードがリーダーを持つかどうかを示します。値が1であれば、クラスター内にリーダーが存在することになります。一方、値が0であれば、クラスター内でリーダーが選出されていないことを意味します。この場合、etcdは動作していないことになります。
# HELP etcd_server_has_leader Whether or not a leader exists. 1 is existence, 0 is not.
# TYPE etcd_server_has_leader gauge
etcd_server_has_leader 1etcd_server_leader_changes_seen_total: etcdクラスターでは、RAFTアルゴリズムのおかげでリーダーが自動的に変更されることがあります。しかし、これは必ずしもetcdクラスターの正常な動作にとって良い、または適切であることを意味するものではありません。このメトリクスが時間とともに継続的に増加している場合、クラスターのパフォーマンスまたはネットワークの問題を示している可能性があります。
# HELP etcd_server_leader_changes_seen_total The number of leader changes seen.
# TYPE etcd_server_leader_changes_seen_total counter
etcd_server_leader_changes_seen_total 1過去1時間以内のetcdのリーダーチェンジを確認できます。この数値が時間とともに増加する場合、同様にクラスター内のパフォーマンスまたはネットワークの問題を示している可能性があります。
max(increase(etcd_server_leader_changes_seen_total[60m]))
etcd_server_proposals_committed_total: コンセンサスの提案は、新しい設定を追加したり、新しい状態を追跡するための書き込み要求のようなものです。 ConfigMap や他のKubernetesオブジェクトのような、構成の変更である可能性もあります。このメトリクスは、クラスターが健全で、変更をコミットしていることを示すため、時間の経過とともに増加するはずです。異なるノードが異なる値を報告するかもしれませんが、これは予想されることであり、再起動後にピアから回復しなければならないとか、リーダーとして最も多くのコミットを持つためなど、さまざまな理由で発生します。あるノードとそのリーダーとの間に大きな一貫した遅れがある場合、そのノードが不健全であったり、性能に問題があることを示すかもしれませんので、すべての etcd メンバーでこのメトリクスを監視することは重要です。
# HELP etcd_server_proposals_committed_total The total number of consensus proposals committed.
# TYPE etcd_server_proposals_committed_total gauge
etcd_server_proposals_committed_total 5.234909e+06
etcd_server_proposals_applied_total: このメトリクスは、適用されたリクエストの総数を記録します。etcdはすべてのコミットを非同期に適用するため、この数値はetcd_server_proposals_committed_total と異なる場合があります。この差は小さいはずです。そうでない場合、あるいは時間とともに大きくなる場合は、etcdサーバーが過負荷であることを示している可能性があります。
# HELP etcd_server_proposals_applied_total The total number of consensus proposals applied.
# TYPE etcd_server_proposals_applied_total gauge
etcd_server_proposals_applied_total 5.234909e+06
etcd_server_proposals_pending: コミットするためにキューに入れられたリクエストの数を表します。高い数値や時間とともに大きくなる数値は、負荷が高いか、etcdメンバーが変更をコミットできないことを示している可能性があります。
# HELP etcd_server_proposals_pending The current number of pending proposals to commit.
# TYPE etcd_server_proposals_pending gauge
etcd_server_proposals_pending 0
etcd_server_proposals_failed_total: リクエストのフェイルは、基本的にリーダーの選出プロセス(変更をコミットできない)やquorumの損失によるダウンタイムが原因です。
# HELP etcd_server_proposals_failed_total The total number of failed proposals seen.
# TYPE etcd_server_proposals_failed_total counter
etcd_server_proposals_failed_total 0
過去1時間以内に何件のプロポーザルが失敗したかを監視することができます。
max(rate(etcd_server_proposals_failed_total[60m]))
Etcdのディスクメトリクス
Etcdは、Kubernetesオブジェクトの状態や定義、設定などを保存するデータベースです。永続的なデータベースであるため、このデータをストレージにバックアップする必要があります。etcdのディスクメトリクスを監視することは、etcdのパフォーマンスについて理解を深め、問題が発生することを予期するための鍵となります。
両方のメトリクスで高いレイテンシーは、ディスクの問題を示し、etcdリクエストで高いレイテンシーを引き起こし、さらにはクラスターが不安定で利用できなくなる可能性があります。
# HELP etcd_disk_wal_fsync_duration_seconds The latency distributions of fsync called by WAL.
# TYPE etcd_disk_wal_fsync_duration_seconds histogram
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.001"} 0
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.002"} 3539
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.004"} 5960
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.008"} 7827
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.016"} 8999
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.032"} 9234
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.064"} 9259
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.128"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.256"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.512"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="1.024"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="2.048"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="4.096"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="8.192"} 9261
etcd_disk_wal_fsync_duration_seconds_bucket{le="+Inf"} 9261
etcd_disk_wal_fsync_duration_seconds_sum 43.74130124199982
etcd_disk_wal_fsync_duration_seconds_count 9261etcd_disk_backend_commit_duration_seconds_bucket: etcd が直近の変更の増分スナップショットをディスクにコミットしている間のレイテンシーです。
# HELP etcd_disk_backend_commit_duration_seconds The latency distributions of commit called by backend.
# TYPE etcd_disk_backend_commit_duration_seconds histogram
etcd_disk_backend_commit_duration_seconds_bucket{le="0.001"} 0
etcd_disk_backend_commit_duration_seconds_bucket{le="0.002"} 0
etcd_disk_backend_commit_duration_seconds_bucket{le="0.004"} 3970
etcd_disk_backend_commit_duration_seconds_bucket{le="0.008"} 4721
etcd_disk_backend_commit_duration_seconds_bucket{le="0.016"} 4860
etcd_disk_backend_commit_duration_seconds_bucket{le="0.032"} 4886
etcd_disk_backend_commit_duration_seconds_bucket{le="0.064"} 4895
etcd_disk_backend_commit_duration_seconds_bucket{le="0.128"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="0.256"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="0.512"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="1.024"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="2.048"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="4.096"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="8.192"} 4896
etcd_disk_backend_commit_duration_seconds_bucket{le="+Inf"} 4896
etcd_disk_backend_commit_duration_seconds_sum 18.608936315999987
etcd_disk_backend_commit_duration_seconds_count 4896バックエンドコミットのレイテンシーが十分かどうかを知るために、ヒストグラムで可視化することができます。以下の PromQL クエリーを実行し、リクエストの 99% がカバーされる時間レイテンシーを取得します。
histogram_quantile(0.99, sum(rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~"etcd"}[5m])) by (le,instance))

etcd_disk_backend_commit_duration_secondsメトリクスは、etcdが直近の変更をディスクにコミットしている間のレイテンシーを測定します。
etcdのネットワークメトリクス
このセクションでは、etcdクラスター周辺のネットワーク状態とアクティビティを監視するために使用できる最適なメトリクスを説明します。
etcd_network_peer_round_trip_time_seconds_bucket: このメトリクスは、ネットワークとetcdノードがどのように機能しているかを測定するためのキーであり、非常に重要です。これは、etcdがetcdメンバー間で要求を複製するためのRTT(往復時間)レイテンシーを示します。高いレイテンシーや時間とともに大きくなるレイテンシーは、ネットワークに問題があることを示し、etcdリクエストに深刻な問題を引き起こし、quorumを失う可能性さえあります。 1回の通信(ピアからピアへ)につき、完全なヒストグラムは1つです。この値は 50ms (0.050s) を超えてはいけません。
# HELP etcd_network_peer_round_trip_time_seconds Round-Trip-Time histogram between peers
# TYPE etcd_network_peer_round_trip_time_seconds histogram
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0001"} 0
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0002"} 0
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0004"} 0
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0008"} 46
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0016"} 55
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0032"} 59
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0064"} 59
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0128"} 112
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0256"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.0512"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.1024"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.2048"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.4096"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="0.8192"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="1.6384"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="3.2768"} 116
etcd_network_peer_round_trip_time_seconds_bucket{To="bf52b1f71736a183",le="+Inf"} 116
etcd_network_peer_round_trip_time_seconds_sum{To="bf52b1f71736a183"} 0.7280363210000003
etcd_network_peer_round_trip_time_seconds_count{To="bf52b1f71736a183"} 116etcdノード間のRTTレイテンシが十分かどうかを知るために、次のクエリーを実行してデータをヒストグラムで可視化します。
histogram_quantile(0.99, sum(rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) by (le,instance))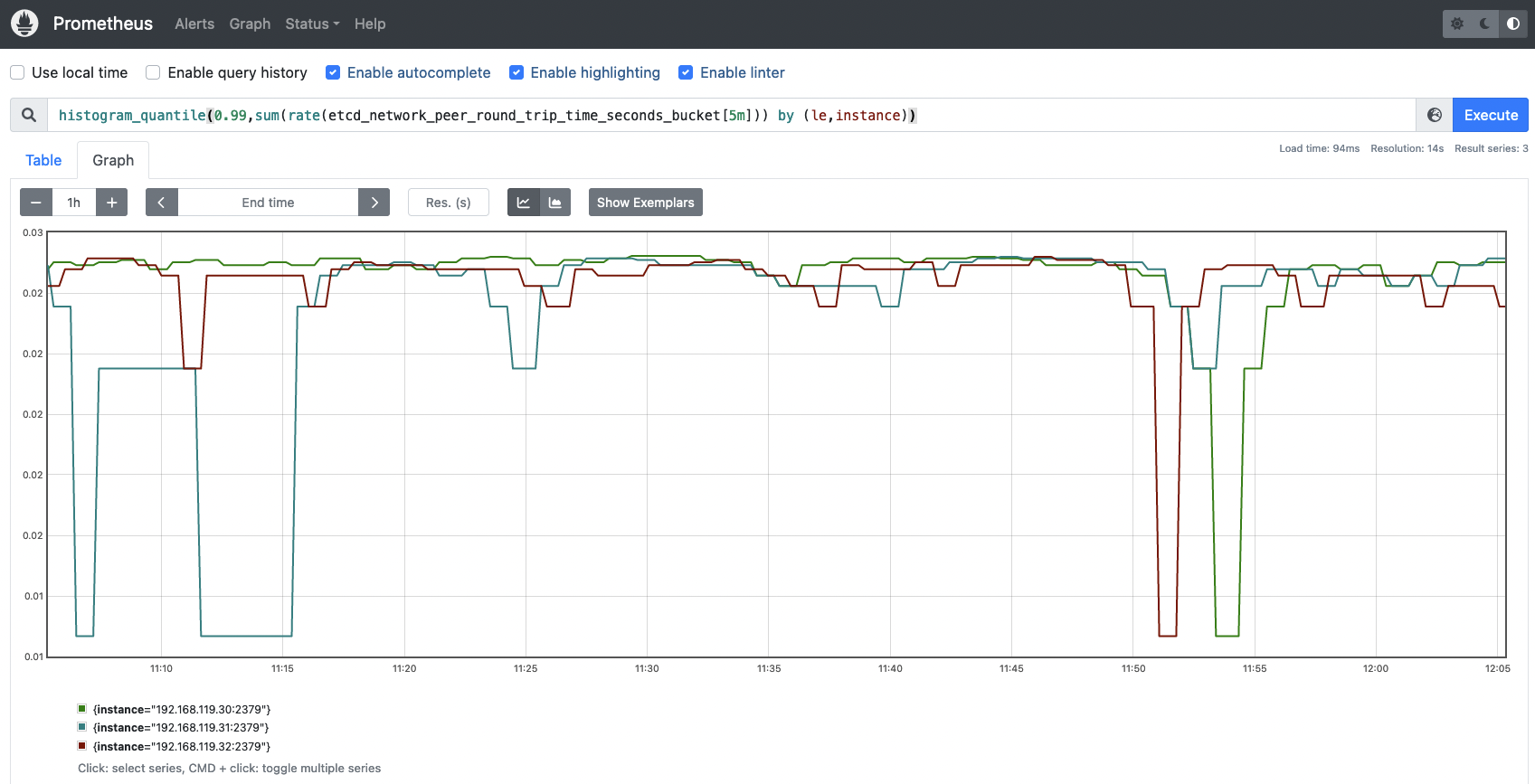
このヒストグラムは、インスタンスごとのネットワークrttを表しています。
etcd_network_peer_sent_failures_total: このメトリクスは、ピアまたはetcdメンバーによって送信されたフェイルの合計数を提供します。これは、特定のノードがパフォーマンスまたはネットワークの問題に直面しているかどうかをよりよく理解するのに役立ちます。
etcd_network_peer_received_failures_total: 前のメトリクスで送信失敗を提供したのと同じように、今回測定されるのは、ピアによる受信失敗の合計です。
まとめ
EtcdはKubernetesの重要なコンポーネントです。etcdが稼働していないと、Kubernetesクラスターは変更を持続することができず、新しいPodもスケジュールされません。
etcdの監視は複雑なトピックです。etcdはそのメトリクスエンドポイントをアウトオブボックスで公開していますが、主要なetcdメトリクスが何であるか、そして健全な環境のために期待される適切な値や期待値に関するドキュメントや一般知識は多くありません。
この記事では、etcdクラスターを監視する方法と、Prometheusインスタンスからそのメトリクスをスクレイピングする方法を学びました。etcdメトリクスに関しては、何を探すべきか、そしてetcdクラスターの可用性とパフォーマンスを測定する方法について詳しく学びました。
etcdの監視と問題のトラブルシューティングを最大10倍高速化します
Sysdigは、Sysdig Monitorに含まれるアウトオブボックスのダッシュボードで、etcdクラスターの監視とトラブルシューティングを支援します。Sysdig Monitorに統合されたツールであるAdvisorは、Kubernetesで稼働するetcdやあらゆるワークロードやサービスのトラブルシューティングを最大10倍まで高速化します。
30日間のトライアルアカウントにサインアップして、ご自身でお試しください!