


Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2022年6月30日にJesus Ángel Samitierが投稿したブログ(https://sysdig.com/blog/monitor-nginx-prometheus/)を元に日本語に翻訳・再構成した内容となっております。
nginx はオープンソースのウェブサーバーで、リバースプロキシ、ロードバランサー、ウェブキャッシュとしてよく利用されます。高負荷の同時接続用に設計されており、高速で汎用性が高く、信頼性が高く、そして最も重要なのは、リソースの消費が非常に少ないことです。この記事では、Prometheusを使ってKubernetes上のnginxを監視する方法と、レイテンシーやサチュレーションなどに関するさまざまな問題をトラブルシューティングする方法について説明します。
構成要素
始める前に、このプロジェクトで使用するツールをまとめておきましょう。
- nginx サーバ (きっとあなたのクラスターですでに動いているはずです!)
- オープンソースの監視標準である Prometheus
- 公式の nginx exporter
- Fluentd と Prometheus 用プラグイン
基本から始める:nginx exporter
Kubernetes上でnginxをPrometheusで監視する場合、まず最初に必要なことはnginx exporterのインストールです。推奨は、nginxサーバのサイドカーとして、デプロイメントに追加するだけでインストールできるようにすることです。以下のような内容である必要があります:apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-server
spec:
selector:
matchLabels: null
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9113'
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-config
mountPath: /etc/nginx/conf.d/default.conf
subPath: nginx.conf
- name: nginx-exporter
image: 'nginx/nginx-prometheus-exporter:0.10.0'
args:
- '-nginx.scrape-uri=http://localhost/nginx_status'
resources:
limits:
memory: 128Mi
cpu: 500m
ports:
- containerPort: 9113
volumes:
- configMap:
defaultMode: 420
name: nginx-config
name: nginx-config
このようにすると、各 nginx サーバー Pod に nginx exporter コンテナが追加さ れることになります。レプリカを 3 つ作成したので、3 つの Pod が作成され、それぞれに 1 つの nginx サーバー コンテナと 1 つの nginx エクスポーター コンテナが含まれることになります。この新しい設定を適用すると、完了です! nginx サーバーから簡単にメトリクスを公開することができます。
Prometheus で nginx 全体のステータスを監視する
うまくいったかどうか確認したいですか?簡単です。Prometheus にアクセスして、以下の PromQL を試してみてください。sum (nginx_up)
これで、3つのコンテナで nginx_up が1つになったと報告されます。メトリクスのことはまだ気にしないでください。
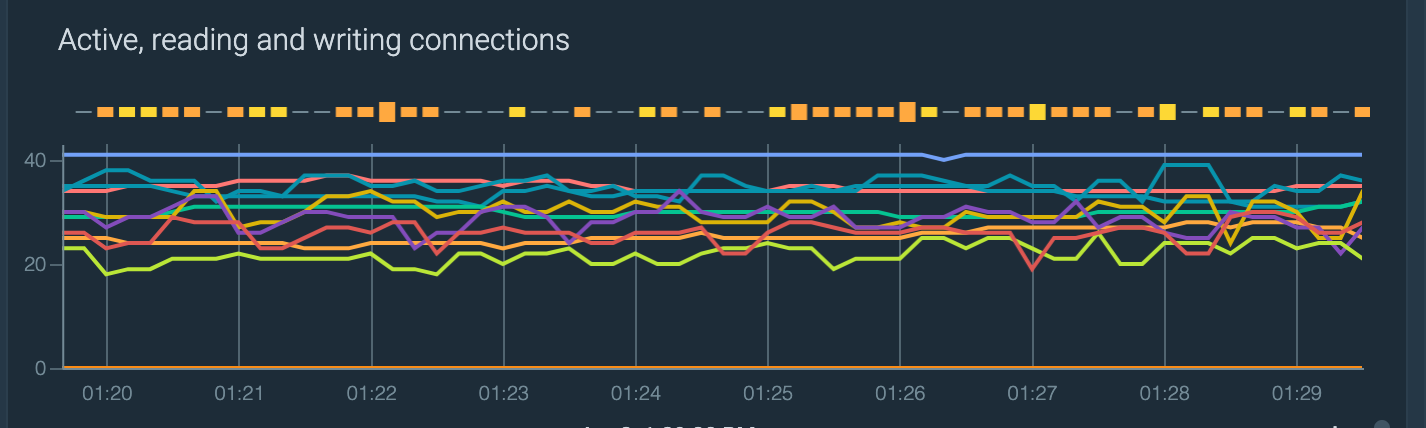
Prometheus で nginx 接続を監視する
アクティブな接続
以下のメトリクスを使って、nginx のアクティブな接続を見てみましょう。どれが読み書きを行っているかに注目することもできます。
nginx_connections_activenginx_connections_readingnginx_connections_writing
これらを使うだけで、こんな感じになります:
未処理の接続
では、nginx で処理されていないコネクションがどれだけあるかに着目してみましょう。受理されたコネクションから処理されたコネクションを取り除けばいいのです。nginx exporter は両方のメトリクスを提供してくれます。
nginx_connections_handlednginx_connections_accepted
では、受け付けられたコネクションのうち、処理されないコネクションの割合を求めてみましょう:rate(nginx_connections_accepted{kube_cluster_name=~$cluster}[$__interval]) - rate(nginx_connections_handled{kube_cluster_name=~$cluster}[$__interval]) or vector(0) / rate(nginx_connections_accepted{kube_cluster_name=~$cluster}[$__interval]) * 100
PromQL をもっと深く知りたいですか?Prometheusがどのようにデータを保存し、PromQLの関数や演算子をどのように使用するかについては、PromQLの入門ガイドをお読みください。

うまくいけば、この数字はゼロに近くなりますよ!
接続待ち
幸いなことに、これも簡単なクエリーです。 nginx_connections_waiting と入力するだけです。これは nginx exporter がこの情報を公開するために使用するメトリクスです。

もっとメトリクスが必要ですか?ログから取得しましょう!
PrometheusでKubernetesのnginxを監視するためにさらに情報が必要な場合、nginxのaccess.logを使ってもう少し情報を取得することができます。その方法を見てみましょう。
オープンソースのデータコレクターであるFluentd
Fluentdを設定することで、nginxのaccess.logから情報を拾って、Prometheusのメトリクスに変換することができます。これは、インスツルメンテッド・アプリケーションがあまり情報を公開しないような状況において、とても便利です。
Fluentd のインストールと設定方法
FluentdとそのPrometheusプラグインについては、すでにここで説明しましたので、その記事の指示に従うだけで、準備は完了します。
Fluentd を設定して、さらにいくつかのメトリクスをエクスポートするようにしましょう
これを行うには、 access.log フォーマットを少し調整する必要があります。デフォルトのログ形式を選択し、最後に $upstream_response_time を追加します。 このように、Fluentdはこの変数を持ち、それを使用していくつかの有用なメトリクスを作成します。name: nginx-config
data:
nginx.conf: |
log_format custom_format '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$upstream_response_time';
server {
access_log /var/log/nginx/access.log custom_format;
...
}
この設定は nginx.conf 、通常は ConfigMap に記述します。
次に、Fluentd が新しいログのフォーマットを読み込むように設定する必要があります。これは Fluentd の fileConfig セクションに nginx 用の新しい config を作成することでできます。<source>
@type prometheus_tail_monitor
</source>
<source>
@type tail
<parse>
@type regexp
expression /^(?<timestamp>.+) (?<stream>stdout|stderr)( (.))? (?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] \"(?<method>\w+)(?:\s+(?<path>[^\"]*?)(?:\s+\S*)?)?\" (?<status_code>[^ ]*) (?<size>[^ ]*)(?:\s"(?<referer>[^\"]*)") "(?<agent>[^\"]*)" (?<urt>[^ ]*)$/
time_format %d/%b/%Y:%H:%M:%S %z
keep_time_key true
types size:integer,reqtime:float,uct:float,uht:float,urt:float
</parse>
tag nginx
path /var/log/containers/nginx*.log
pos_file /tmp/fluent_nginx.pos
</source>
<filter nginx>
@type prometheus
</filter>
この設定で、基本的には nginx の access.log 用の正規表現パーサーを作成しました。これは expression の設定です。expression /^(?<timestamp>.+) (?<stream>stdout|stderr)( (.))? (?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] \"(?<method>\w+)(?:\s+(?<path>[^\"]*?)(?:\s+\S*)?)?\" (?<status_code>[^ ]*) (?<size>[^ ]*)(?:\s"(?<referer>[^\"]*)") "(?<agent>[^\"]*)" (?<urt>[^ ]*)$/
例えば、このログ行を見てみましょう:2022-06-07T14:16:57.754883042Z stdout F 100.96.2.5 - - [07/Jun/2022:14:16:57 +0000] "GET /ok/500/5000000 HTTP/1.1" 200 5005436 "-" "python-requests/2.22.0" 0.091
パーサーで、そのログ行を以下の部分に分解してみました:
timestamp: 2022-06-07T14:16:57.754883042Zstream: stdoutremote: 100.96.2.5host: -user: -time: 07/Jun/2022:14:16:57 +0000method: GETpath: /ok/500/5000000status_code: 200size: 5005436referer: -agent: python-requests/2.22.0urt: 0.091
これで、Fluentd が access.log を読むように設定されたので、パーサーから得られたこれらの変数を使用して、いくつかのメトリクスを作成することができます。
nginx 送信バイト数
size 変数を使って nginx_size_bytes_total メトリクスを作成することができます: nginx の総送信バイト数を表すカウンターです。<metric>
name nginx_size_bytes_total
type counter
desc nginx bytes sent
key size
</metric>
エラーレート
このシンプルなメトリクスを作成してみましょう:<metric>
name nginx_request_status_code_total
type counter
desc nginx request status code
<labels>
method ${method}
path ${path}
status_code ${status_code}
</labels>
</metric>
このメトリクスは、すべてのログ行をカウンターにしただけのものです。では、なぜそれが有用なのでしょうか?まあ、他の変数をラベルとして使うことができるので、すべての情報を分解するのに便利でしょう。このメトリクスを使って、全体のエラー率パーセンテージを取得してみましょう:sum(rate(nginx_request_status_code_total{status_code=~"[4|5].."}[1h])) / sum(rate(nginx_request_status_code_total[1h])) * 100
また、この情報を method別に集計して得ることもできます:sum by (method) (rate(nginx_request_status_code_total{status_code=~"[4|5].."}[1h])) / sum by (method) (rate(nginx_request_status_code_total[1h]))
あるいは、 path別でも:sum by (path) (rate(nginx_request_status_code_total{status_code=~"[4|5].."}[1h])) / sum by (path) (rate(nginx_request_status_code_total[1h]))
レイテンシー
成功したリクエストのレイテンシーを監視できたら素晴らしいと思いませんか?そうです、あなたの誕生日かもしれません! なぜなら、それができるからです。 $upstream_response_time 変数を追加するように指示したのを覚えていますか?
この変数はアップストリームサーバーからレスポンスを受け取るのに費やされた時間を秒単位で保存します。Fluentdでヒストグラムのメトリクスを作成するには、このようにします:<metric>
name nginx_upstream_time_seconds_hist
type histogram
desc Histogram of the total time spent on receiving the response from the upstream server.
key urt
<labels>
method ${method}
path ${path}
status_code ${status_code}
</labels>
</metric>
さて、魔法のように、この PromQL クエリーを試すと、成功したすべてのリクエストのレイテンシーを、リクエストのパスによって集約して p95 で取得することができます。histogram_quantile(0.95, sum(rate(nginx_upstream_time_seconds_hist_bucket{status_code !~ "[4|5].."}[1h])) by (le, path))
まとめると
今回は、Kubernetes上のnginxをPrometheusで監視する方法と、Fluentdを使ってnginxのaccess.logを読み、さらにメトリクスを作成する方法について学びました。また、Prometheusでnginxを監視しトラブルシュートするための興味深いメトリクスを学びました。