


Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2023年2月8日にPANHARITH CHHUMが投稿したブログ(https://sysdig.com/blog/prometheus-alertmanager)を元に日本語に翻訳・再構成した内容となっております。Zoomコールでオンコールチームのサウンドを聞きながら眠ってしまったことはありませんか?不幸にもこのような経験をされた方は、アラート疲労の問題を身をもって理解されていることでしょう。インシデントが発生している間、端末とアラートを切り替えながら、下流のノイズから上流の根本原因を突き止めるのは大変な作業です。そこでAlertmanagerの登場です。アラート疲労に関連する各問題を軽減する方法を提供します。この記事では、以下を学びます。
- アラート疲れとは何か
- AlertManagerとは
- ルーティング
- 抑制
- サイレンシングとスロッ トリング
- グループ化
- 通知テンプレート
アラート疲労
アラート疲労とは、優先順位が低く、対処できないアラートに頻繁に応答することで疲弊することです。これは、長期的にみて持続可能ではありません。すべてのアラートが、開発者を目覚めさせるほどの緊急性を持っているわけではありません。オンコールの週を持続可能なものにするには、睡眠にも優先順位をつける必要があります。
- 今週、あるエンジニアは2回以上起こされたでしょうか?
- 解決は自動化できるか、朝まで待てるか?
- 何人の人間が関わったか?
企業はしばしば応答時間や解決にかかる時間に注目しますが、オンコールプロセスが燃え尽き症候群の原因になっていないことをどのように確認するのでしょうか?
ペインポイント機能Alertmanager適切なチームへのアラート送信ルーティングラベル付けされたアラートは、対応するレシーバーにルーティングされる一度に多くのアラートが届く抑制アラートは他のアラートを抑制することができます(例:データセンターダウンのアラートはダウンタイムのアラートを抑制する)。アラートの誤検知サイレンシング定期メンテナンス時など、一時的にアラートを静かにさせることができます。アラートの頻度が多すぎるスロッ トリング頻繁な再通知を避けるためのバックオフオプションをカスタマイズ可能未整理のアラートグルーピング'environment=dev' や 'service=broker' などのラベルでアラートを論理的にグループ化する通知の形式がバラバラ通知テンプレートアラートをテンプレートに標準化し、サービス間でアラートが構造化されるようにする
Alertmanager
Prometheus Alertmanagerは、アラートをエンジニアリングチームのためのアラート通知に変換するためのオープンソースの標準です。Alertmanagerは、1ダースのアラートが1ダースのアラート通知になるはずだという仮定に挑戦します。Alertmanagerの機能を活用することで、数十のアラートを数個のアラート通知に集約することができ、オンコールエンジニアはアラートではなくインシデントという観点から考えることで、コンテキストスイッチを減らすことができます。
ルーティング
ルーティングとは、Slack、Pagerduty、メールなど様々な受信者にアラートを送信する機能です。Alertmanagerの中核をなす機能です。route:
receiver: slack-default # Fallback Receiver if no routes are matched
routes:
- receiver: pagerduty-logging
continue: true
- match:
team: support
receiver: jira
- match:
team: on-call
receiver: pagerduty-prod
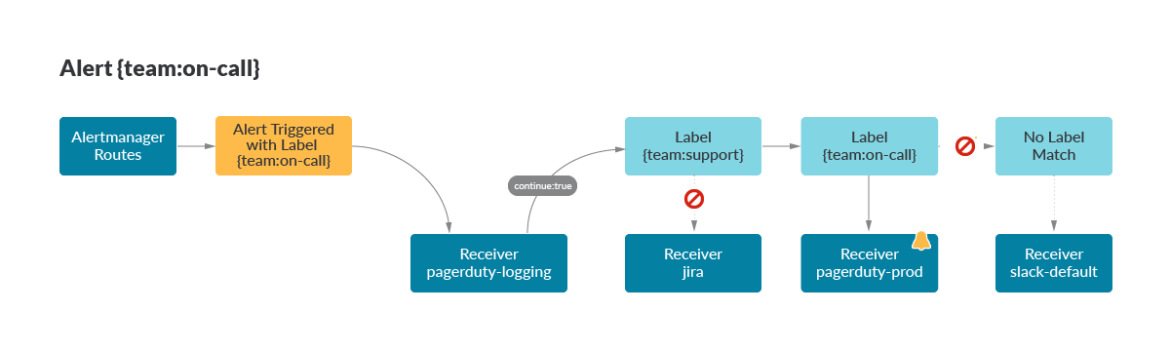
ここでは、{team:on-call}のラベルを持つアラートがトリガーされました。ルートは上から下へマッチングされ、最初のレシーバーはpagerduty-loggingで、オンコール管理者が各月末にすべてのアラートを追跡するためのレシーバーです。このアラートには {team:support} ラベルがないため、マッチングは{team:on-call} に続き、そこでアラートは pagerduty-prod レシーバーに適切にルーティングされます。マッチングが成立しない場合に備えて、デフォルトルートであるslack-defaultがルートの先頭に指定されています。
抑制(Inhibition)
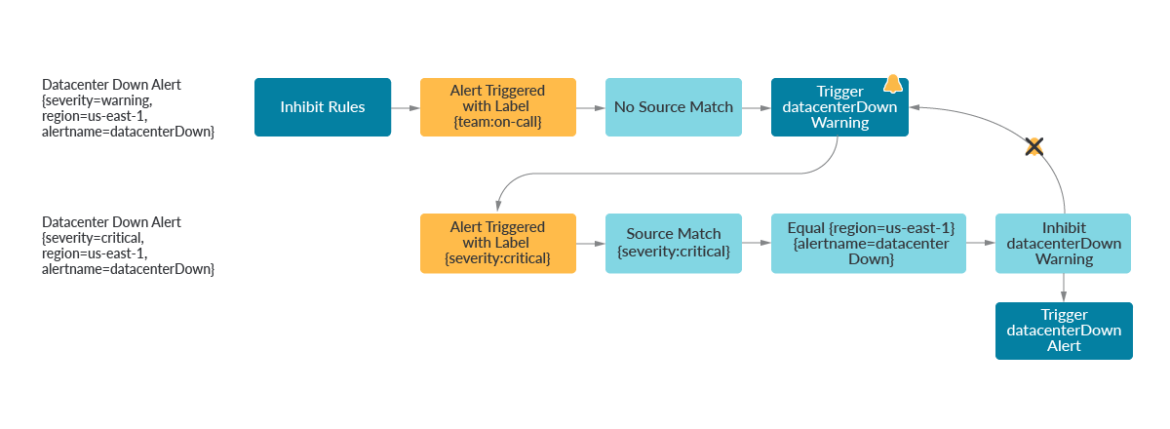
抑制は、ラベルセットに応じて下流のアラートをミュートする処理です。もちろん、これはアラートが論理的かつ標準的な方法で体系的にタグ付けされなければならないことを意味しますが、それは人間の問題であり、Alertmanagerの問題ではありません。アラートしきい値のネイティブサポートはありませんが、ユーザーはラベルを利用し、クリティカルコンディションが満たされたときにアラートを禁止することができます。これは、スカラー比較を使用しないアラートの条件をサポートするというユニークな利点があります。CPU使用率60%でアラートし、CPU使用率80%でアラートするのは良いことですが、2つのクエリーを比較するワーニングとアラートを作りたかったらどうでしょうか?このアラートは、ノードのポッドが容量より多くなったときにトリガーされます。(sum by (kube_node_name) (kube_pod_container_status_running)) >Alertmanagerで抑制を使うことで、まさにこのようなことができます。最初の例では、
on(kube_node_name) kube_node_status_capacity_pods{severity=critical}のラベルを持つアラートは、同じリージョンとalertnameを共有している場合、{severity=warning}のアラートを抑制することができます。2番目の例では、根本的な原因において重要でないことが分かっている場合、下流のアラートを抑制することもできます。Kafkaプロデューサーがトピックに何もパブリッシュしていないときに、Kafkaコンシューマーが異常な動作をすることが予想されるかもしれません。inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['region','alertname']
- source_match:
service: 'kafka_producer'
target_match:
service: 'kafka_consumer'
equal: ['environment','topic']
サイレンシングとスロットリング
夜中の2時に根本原因のアラートで目が覚めた今、そのアラートを認めて是正に移りたいと思うのではないのでしょうか。アラートを解決するには時期尚早ですが、アラートの再通知では余計な情報が入ってきません。そこで、サイレンシングとスロットリングが役に立ちます。サイレンシングは、データベース メンテナンスなどのスケジュールされた手順でアラートがトリガーされることを予期している場合、またはインシデント中にすでにアラートを確認し、修復中に再通知されないようにしたい場合に、アラートを一時的にスヌーズすることを可能にします。スロットリングは、同じような問題を解決しますが、少し異なる方法です。スロットリングでは、3つの主要なパラメータを使用して再通知設定を調整することができます。
- group_wait
- group_interval
- repeat_interval
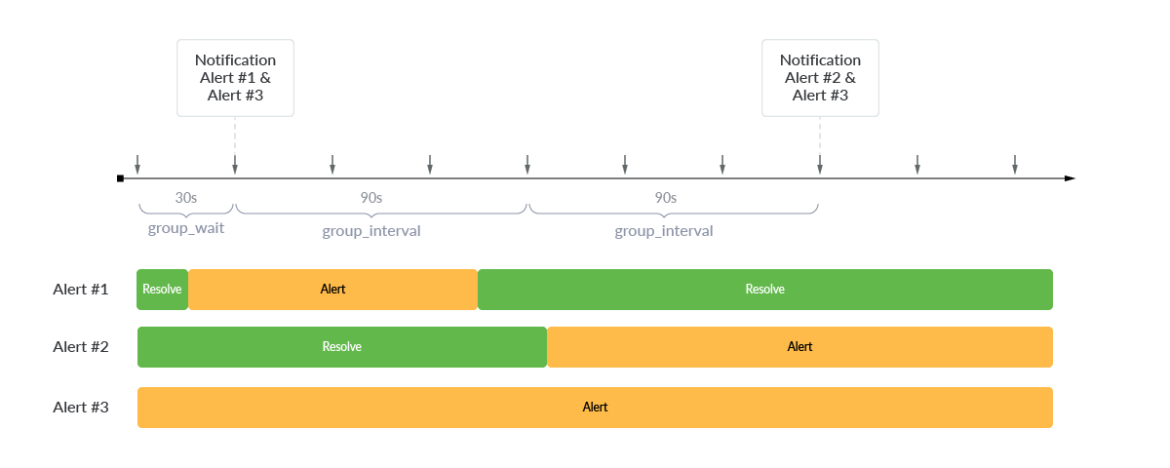
アラート#1とアラート#3が最初にトリガーされたとき、Alertmanagerはgroup_waitを使用して、通知前に30秒遅らせます。最初のアラートがトリガーされた後、新しいアラート通知はgroup_intervalで遅延されます。次の90秒間は新しいアラートがないため、通知はありません。しかし、その後の90秒間にアラート#2がトリガーされ、アラート#2とアラート#3の通知が送信されました。新しいアラートがトリガーされなかった場合、現在のアラートを忘れないために、repeat_intervalは、現在トリガーされたアラートが24時間ごとに再通知を送信するように、24時間などの値に構成することができます。
グルーピング
Alertmanagerのグルーピングは、同じラベルセットを共有する複数のアラートを同時に送信することを可能にします-グループ内のアラートルールが順次評価されるPrometheusのグルーピングと混同しないようにしましょう。デフォルトでは、与えられたルートに対するすべてのアラートは一緒にグループ化されます。group_by フィールドを指定すると、アラートを論理的にグループ化することができます。route:
receiver: slack-default # Fallback Receiver if no routes are matched
group_by: [env]
routes:
- match:
team: on-call
Group_by: [region, service]
receiver: pagerduty-prod
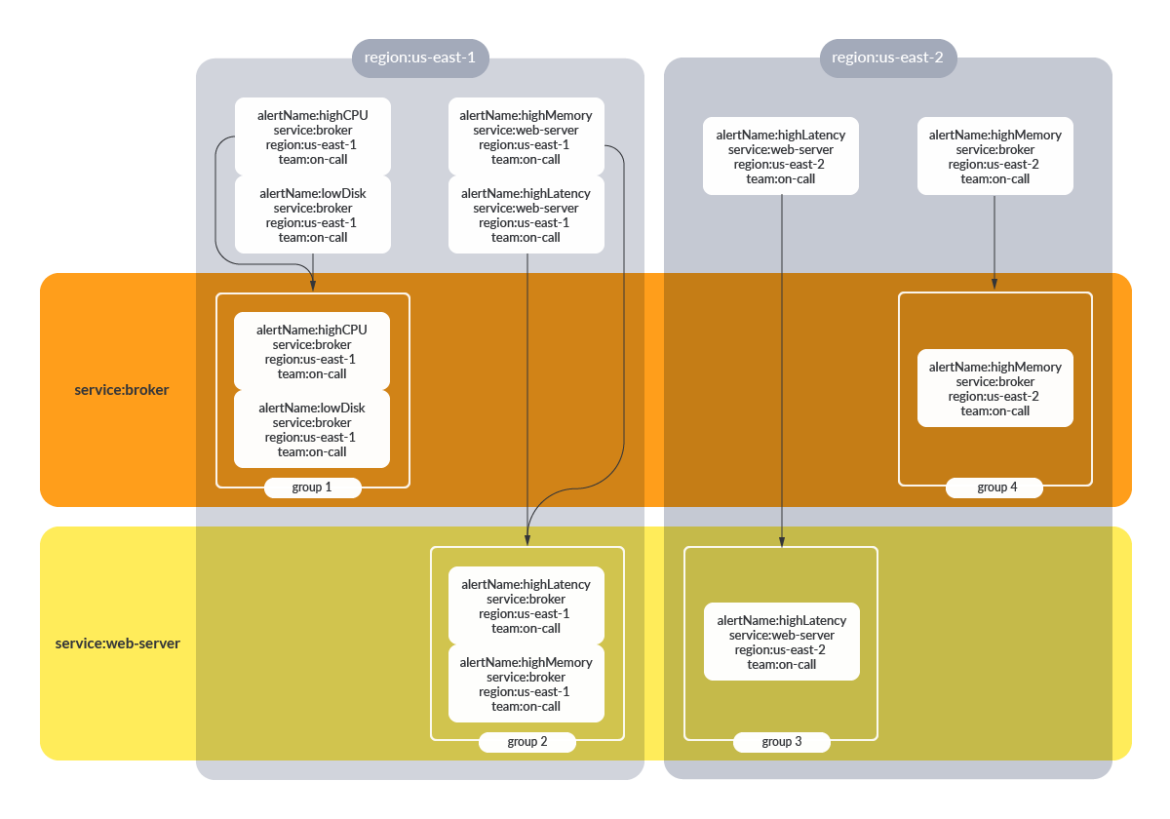
{team:on-call}のラベルを持つアラートは、リージョンとサービスの両方によってグループ化されます。これにより、ユーザーは、このアラートグループ内のすべての通知が同じサービスとリージョンを共有しているというコンテキストをすぐに把握することができます。instance_idやip_addressなどの情報によるグループ化は、一意のinstance_idやip_addressがそれ自身の通知グループを生成することを意味するので、あまり有用でない傾向があります。これは、ノイズの多い通知を生成し、グループ化の目的を失うかもしれません。グループ化が設定されていない場合、すべてのアラートは、与えられたルートに対して同じアラート通知の一部となります。
通知テンプレート
通知テンプレートは、アラート通知をカスタマイズし、標準化する方法を提供します。例えば、通知テンプレートは、ラベルを使用して、自動的にRunbookにリンクしたり、オンコールチームがコンテキストを作成するために有用なラベルを含めることができます。ここでは、アプリとアラートネームのラベルは、Runbookにリンクするパスに挿入されています。通知テンプレートを標準化することで、オンコール・プロセスをよりスムーズに実行できます。オンコール・チームは、ページングを行うマイクロサービスの直接のメンテナではないかもしれないからです。receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: 'https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}'
Sysdig Monitorでアラートをワンクリックで管理
組織が大きくなるにつれ、PrometheusとAlertmanagerをチーム横断で管理することが困難になってきます。Sysdig Monitorは、ロールベースのアクセスコントロールにより、各チームが最も重要なメトリクスとアラートに集中できるようにします。Sysdig Monitorは、お客様が1つの画面でアラートを管理できるターンキー・ソリューションを提供しています。Sysdig Monitorを使えば、Prometheus Alertmanagerのメンテナンスに費やす時間を減らし、実際のインフラストラクチャーの監視により多くの時間を費やすことができるようになります。監視とアラートのエキスパートであるSysdig Monitorにご相談ください。

Sysdig Monitorの無料トライアルに今すぐサインアップしてください。