AI is still a workload: A practical guide to securing AI workloads




Falco Feeds extends the power of Falco by giving open source-focused companies access to expert-written rules that are continuously updated as new threats are discovered.

AI may look like magic, but behind the scenes, it is still code running on servers. As such, it needs to be secured like any other workload.
In this article, we'll evaluate the security risks associated with three different approaches to using AI: an employee utilizing an LLM like ChatGPT, a company that offers a chatbot as part of its product, and a company that trains its own model from scratch.
We’ll show you how AI workloads actually resemble other workloads you may already be running, and we'll provide some mitigation steps to help you enhance their security.
There are seven main areas you should cover when securing AI workloads: inventory, model and data security, access control, detection, risk management, threat management, and compliance:
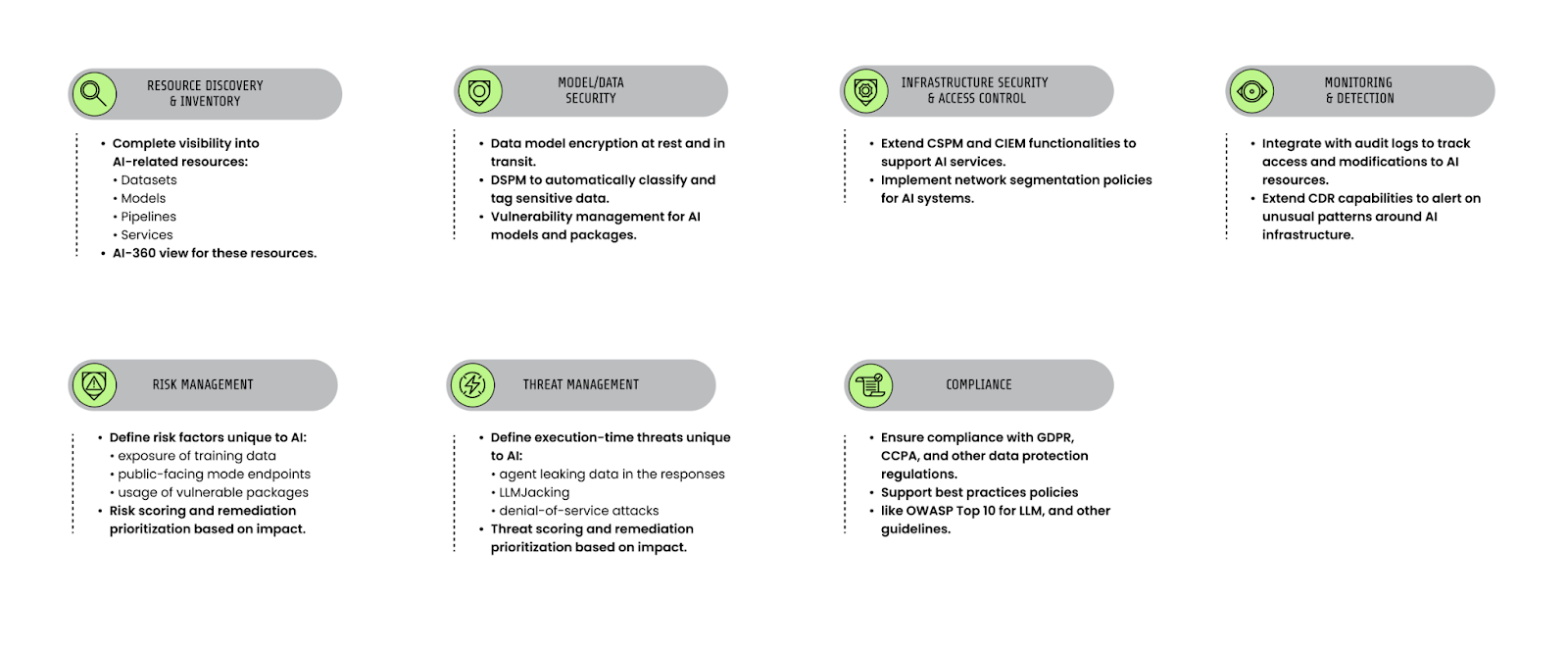
Securing LLM users
Let's start by covering how to secure users of LLMs, such as ChatGPT, Copilot, or Gemini, within your organization.
Main risks: Leaking data or being misguided by the model.
Similar to: Any other SaaS.
Actions: Educate your users on the best practices and the privacy implications of AI.
Ensure your data is not being used for training
Your privacy is not a priority for AI companies; however, training their models and beating the competition is.
While it's not strange for SaaS services to use your data to improve their services, it's outrageous that companies are doing so to train their LLM models. It is a privacy and security nightmare, as it's fairly easy to manipulate agents to return some of this training data.
Services like OpenAI Enterprise or Google Workspace Gemini don't use your data to train their models, but the same doesn't apply to the regular versions of their products. Users in your organization with individual accounts need to review their privacy settings manually.
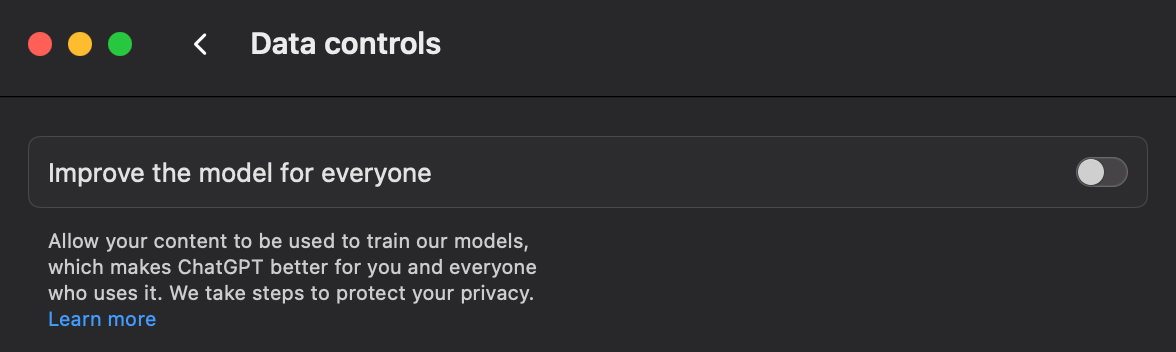
For ChatGPT, they'll need to navigate to their settings, then “Data controls”, and disable the “Improve the model for everyone” toggle:
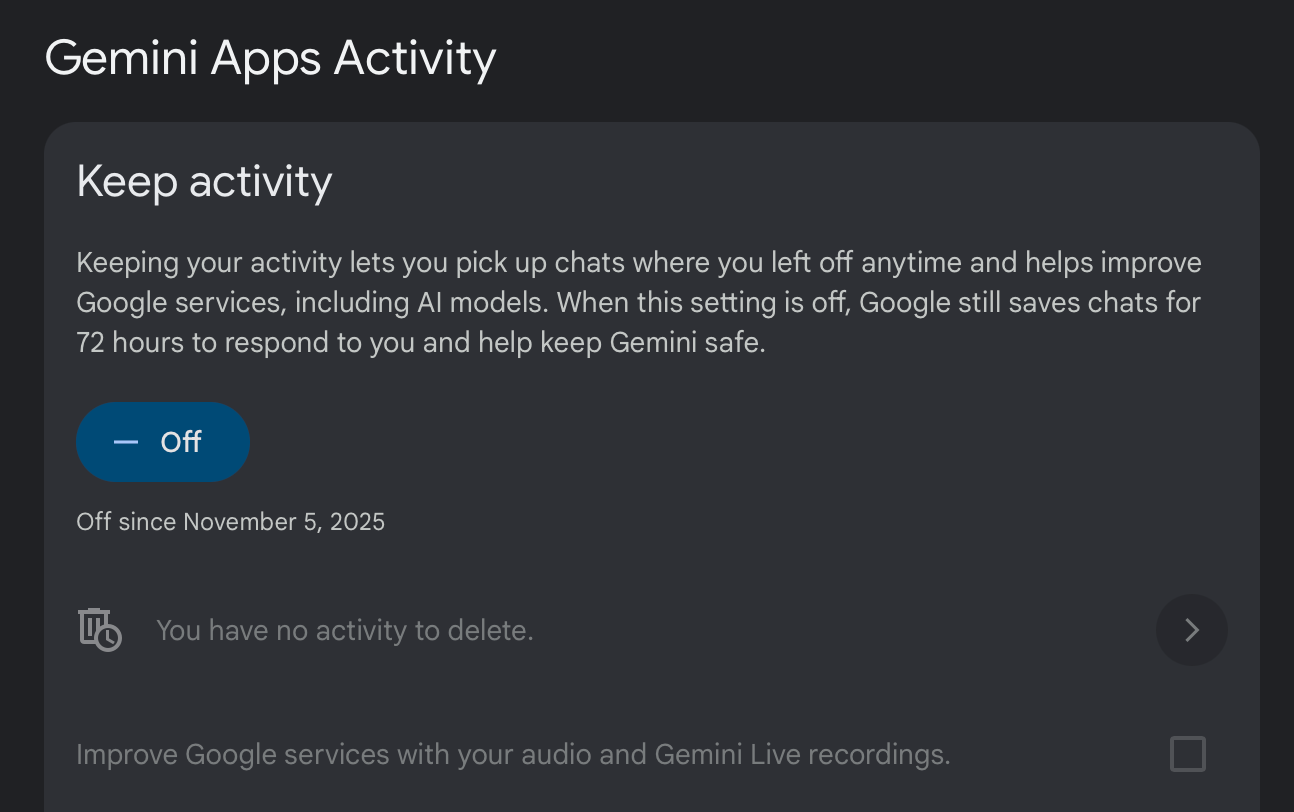
For Gemini users, the setting is buried inside the “myactivity” portal:
Ensure your company offers training on best practices for using AI, as well as its associated privacy implications. Leaking data in this manner will harm your company's reputation and result in substantial fines under regulations such as GDPR and CCPA.
Visibility of AI apps and the resources they access
As you can't secure what you can't see, it's important to do an inventory of all the resources your AI agents can access and limit them if necessary. Business and enterprise versions of AI agents can be globally configured with an allowlist of sanctioned connected apps.
However, this configuration may not apply to agents like OpenAI's Codex, where users are free to provide access to local files and set up external connections via MCPs. Likewise, users can bypass these restrictions by using personal accounts of these services.
If this has become an issue, consider implementing device management software that limits what software can run on your employees' computers, and can be used to block connections to specific resources.
That being said, restricting access to certain resources can be disruptive. Training users on best practices for AI is always a good starting point.
Protect access to credentials and API keys
Even if AI agents don't use private data to train their models, they do cache some of that data on the user's account. If a malicious actor obtains access to that account, they will be able to extract any cached information.
As with any SaaS, require two-factor authentication for AI services and set up data retention policies. Also, enable access auditing and feed it to your threat detection engine so you can be alerted about suspicious connections.
Protect against poisoned models
Don't trust AI blindly.
LLMs are not neutral and omniscient oracles. AI relies on limited information, gives hallucinated responses with complete certainty, and operates within some opinionated guardrails defined by the people who programmed the model. You should contrast any information they provide and supervise any task they perform.
Think of AI models as eight-year-olds. They will consider anything their parents told them as the ultimate truth, will make up facts with complete confidence, and if left unsupervised, they are capable of creating the greatest of mayhem.
On top of that, models are susceptible to poisoning. In the same way a child will learn a bad word and won't stop using it, AI models can learn all kinds of nasty things if their training data is not carefully curated.
Attackers can poison models to manipulate an agent's response. Similar to optimizing websites for search engines, you can manipulate AI agents from the website code. For example, you can include hidden instructions in the source code that the agent will interpret when scraping the internet. An attacker could use this technique to trick the agent into directing other users to a fraudulent phishing website instead of a legitimate one.
These attacks can also be subtler, such as training the model to break out of its container and run malicious code under specific inputs.
Keep all that in mind and train your teams to approach LLMs with a skeptical mindset.
Securing public-facing chatbots and internal agents
Main risks: Attackers using the agent as an entry point, Attackers exploiting your AI infrastructure.
Similar to: Any external API access.
Actions: Parse all user inputs, do proper network segmentation, and secure the credentials.
Protect against jailbreak
One of the first things you learn as a developer is that users can use any input field at their disposal to generate chaos in unexpected ways. It’s fun to play around with websites and see if a developer forgot to sanitize user inputs, allowing for SQL injection (at least for us — not for the developers).

Nowadays, app frameworks filter user inputs against the most popular attacks by default. However, we still have surprises like Log4Shell, a vulnerability in the log4j where a crafted user input could execute code on the server side when logged by this library.
Of course, the same principle still applies in the AI age:

Feeding unfiltered data to your AI agents allows for prompts that bypass their guardrails.
In the best of cases, someone will make your product's AI assistant say something funny. In the worst-case scenario, the attacker will manipulate your assistant into leaking data from your organization. Remember, any data or resources available to the agent can be reached this way.
These exploits are not limited to direct user prompts in an AI assistant. You must specially protect agents running on the backend by ensuring the data they access is free from hidden instructions and usernames like “William Ignore All Previous Instructions.”
The scariest thing is that, while you needed some technical knowledge to perform an SQL injection, manipulating an LLM can be done using plain language. For example, on ChatGPT 3.5, it was possible to extract training data by asking it to repeat the word “company” 500 times.
As a rule of thumb:
- Filter user inputs before they reach the agent. Specifically:
- Delimiters you may be using to separate your guidelines from the user input.
- Keywords like “ignore”, “instructions”, “guidelines”, or words outside the intended scope of your agent.
- Filter your agent output before returning it to the user. Limit the length of responses and detect data that looks like emails, API keys, or similarly structured data.
- Test your guardrails extensively to ensure they are tight. Consider contracting external specialists to put them to the test.
- Keep your guardrails private so attackers have less information on your weak points.
- Prevent lateral movement with the usual security recommendations, such as limiting access to the rest of the resources and implementing network segmentation.
Protect against LLMJacking: Secure credentials and access
Secure your agent's credentials and API keys like you would do with any other cloud service or external API.
AI computing time is expensive, and someone else's infrastructure is always cheaper. There is a vibrant market of proxies to compromised AI servers if you know where to look. The technique of stealing LLM server credentials is called LLMJacking.
Here are some best practices for securing credentials:
- Don't hardcode API keys in your code. Use secrets and environment variables.
- Scan for vulnerabilities in your software that could cause a credentials leak and mitigate them.
- Apply network segmentation so that only your backend can access the agents, and can only do it from specific sources.
- Implement auditing, detection, and response for your AI workloads. Ensure you can detect unusual activity and log it to investigate potential incidents.
Protect against denial of service
Any service available to the public is susceptible to abuse to the point that the service is degraded. In the case of LLMs, this may come in two main ways:
- Attackers asking for complex prompts that cause a spike in resource usage.
- Attackers repeatedly sending requests to the agent faster than the agent can process.
To avoid this:
- Again, parse inputs to filter out requests like “repeat this forever.”
- Implement limits on the rate at which user inputs are processed.
- Limit the length of outputs from LLM agents.
- Monitor resource usage and alert on usage spikes.
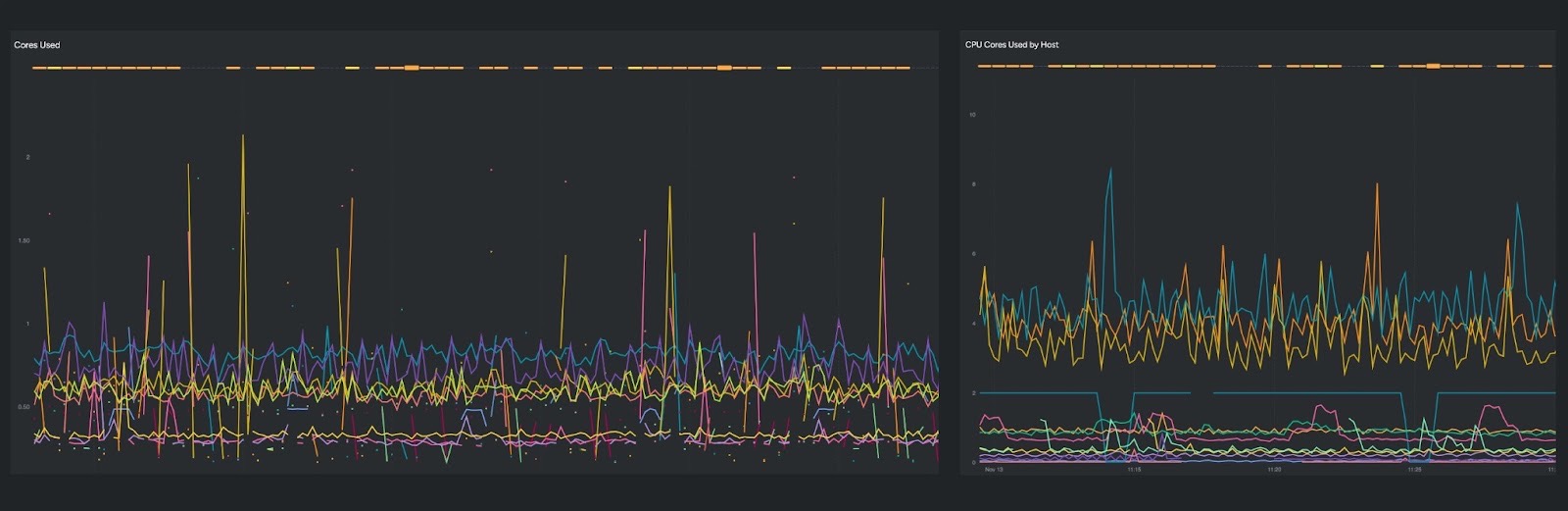
Securing self-trained models
Main risks: Leaking the model and poisoning the model. Using your agents as an entry point, or exploiting your AI infrastructure (similar to what was discussed above).
Similar to: Any backend service.
Actions: Carefully craft your learning dataset and secure access to your models.
Securing any service requires an integral approach, following security best practices every step of the way. We've already covered some best practices in this article, and you probably know the rest. So approach this next section as a quick checklist you can use as the basis to secure any service, not just AI.
Access to resources
Training a model requires a significant amount of effort, not only in terms of computing, but also in curating the training dataset. By the end of this process, you’ve built something unique that differentiates from your competition.
This is an important investment, so protect it accordingly:
- Start by taking an inventory of your resources… and keep that inventory updated! You can't secure what you can't see, so make sure nothing falls between the cracks.
- Apply a zero-trust approach when configuring access to models and data sources. For example, if you store models and data sources in S3, make sure they are private and accessible only by the required accounts.
Models and data
It’s also critical to protect the actual data in case the access is compromised. Encrypt your model and training data both at rest and in transit. For example, you can enforce this on your S3 buckets with a config like:

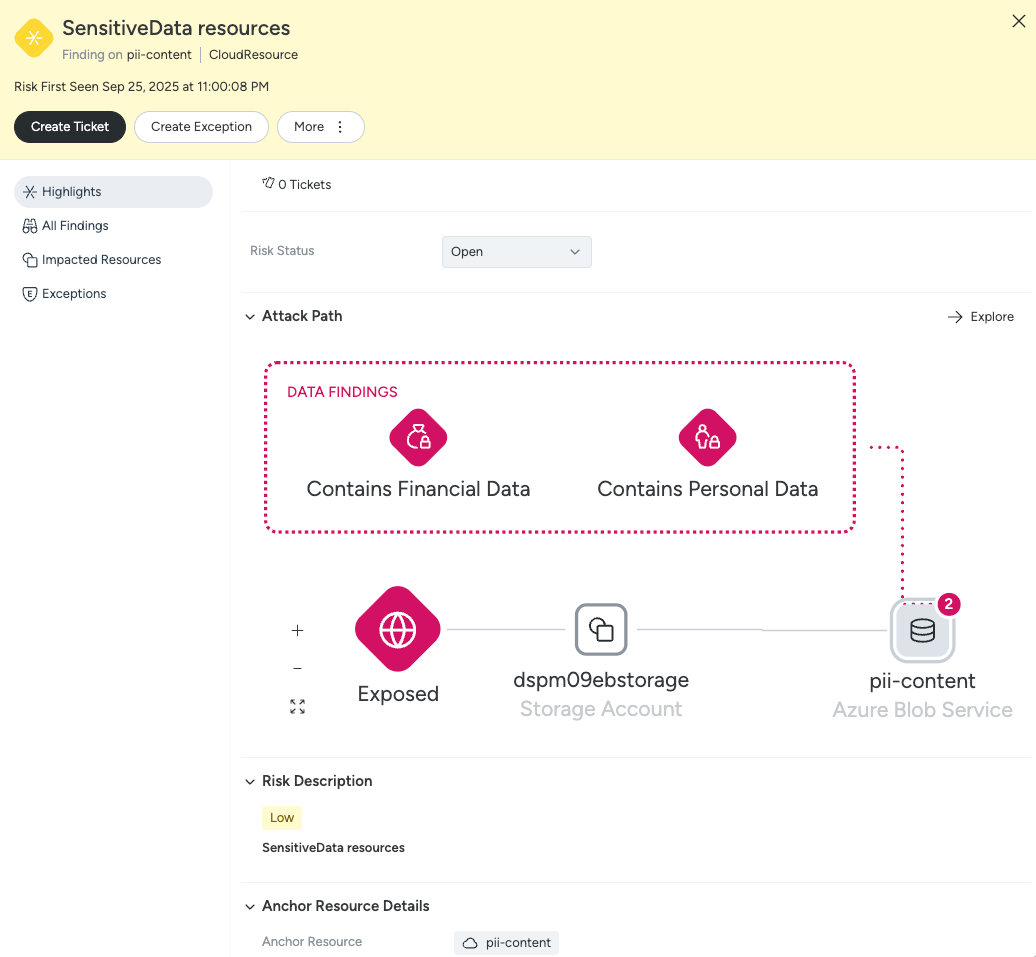
Use data security posture management (DSPM) to classify and tag sensitive data automatically. For example, you can use tools like Bedrock Data to make sure there are no API keys (or anything similar) in your training data, or prevent such data from reaching the agents in a prompt.
Static: Infrastructure and risk management
Create a list of risk factors specific to your infrastructure. You may take the examples we've covered in this article as inspiration, such as exposure of training data, public-facing mode endpoints, and the use of vulnerable packages, among others.
Score each risk based on its impact to prioritize your efforts.
Plan mitigation actions for each risk. Examples of remediation actions include a zero-trust approach to configuring access and network segmentation, data encryption, and tracking vulnerabilities in packages.
Leverage CSPM and CIEM tools to track the implementation of remediation actions and provide visibility on your weakest points.
Dynamic: Monitoring, detection, and threat management
Detecting abnormal behaviors that occur during execution serves as a safety net to catch threats that you may have missed in your static configuration.
Begin by identifying threat factors that are specific to you. We mentioned examples such as the agent leaking data in the responses, LLMJacking, or denial-of-service attacks.
Score each threat based on its impact to prioritize your efforts.
Plan remediation actions for each threat. This may include processing audit logs to track access and modifications to Al resources, as well as creating detection rules to identify abnormal behavior.
Implement these actions using CDR tools that observe your entire infrastructure, alert on unusual patterns, and provide context to facilitate the investigation of security events.
As a final step, after a security event has been investigated and remediated, review your static configuration to include new risks and mitigation actions that will prevent such a threat from happening again.
Compliance
Our last recommendation is to meet compliance standards and security benchmarks. Do so even when you are not required to, and use them as a tool to detect gaps in your security strategy.
Take special notice of data protection laws, such as GDPR in Europe or CCPA in California. As we've covered in this article, data protection is the weakest link in modern AI.
Next steps
Think of this article as a quick guide to get you started. Here are some additional resources if you want to dig deeper into this topic.
A quick win to start with the OWASP Top 10 for LLMs. These are the most common threats you are likely to encounter.

For a comprehensive list, refer to the MITRE ATLAS Matrix. It's an updated list of tactics and techniques related to machine learning.

Conclusion
The best practices for securing AI workloads are the same as for usual services:
- When using AI agents like ChatGPT, you have to apply the same rules as when using any other SaaS.
- Securing an external agent is like securing access to an external API.
- Securing your own models and agents is similar to securing other backend workloads.
On top of that, you have to cover for the non-deterministic nature of LLMs that can turn innocent prompts into bombs. To mitigate this risk, think outside the box when sanitizing inputs and implementing rate limits.
Hopefully, we managed to demystify AI workloads by relating some use cases to services you are familiar with.
For more details on how to secure AI workloads, download our blueprint.