

Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2026年3月26日に Manuel Boira が投稿したブログ(https://www.sysdig.com/blog/ai-infrastructure-security-why-it-deserves-its-own-category)を元に日本語に翻訳・再構成した内容となっております。
人工知能インフラストラクチャーへの攻撃は増加していますが、その形は多くの人が予想するものとは異なります。AIセキュリティに関する見出しではプロンプト操作に注目が集まっていますが、攻撃者はこうしたシステムの背後にあるインフラストラクチャーを狙っています。この記事では、AIセキュリティをより広い視点から捉え、この変化を読み解くとともに、それに対応するための実践的な戦略を示します。
そのリスクを理解するために、セキュリティエンジニアの立場になって考えてみてください。
ある何気ない金曜日の午後、小売業者のセキュリティチームは警告を受け取ります。顧客の住所や銀行情報が地下フォーラムで出回っているというのです。これは予想外の知らせです。本番システムは厳重に監視されており、データは分割されていて、データ持ち出しも検知されていません。
調査は不穏な展開を見せます。情報源は堅牢化されたeコマースプラットフォームではなく、実際の顧客データを使ってレコメンデーションモデルを訓練している、新たに作成されたAIリサーチ環境でした。それは本番環境ではありません。公開される想定でもありません。それでもクラウド上で稼働しているのです。
このシナリオは仮説です。しかし、リスクのパターンは仮説ではありません。
結局のところ、それはクラウドインフラストラクチャーに関することなのです
AIワークロードはまだ初期段階にあり、いまだ実験的な雰囲気をまとっていますが、それを支えるインフラストラクチャーは現実のものであり、そこで扱われるデータは多くの場合、膨大で機微なものです。そのため、リスク領域は通常、チームが当初想定するよりも大きくなります。
AIは魔法のように見えるため、人々はそれに対して警戒を緩めがちです。これをより明確にするために、まず直感的ではない点をはっきりさせましょう。
抽象化を取り払ってしまえば、AIも結局はどこかで稼働しているワークロードにすぎません。
本当の問いは、AIがコンピューティングサービスに依存しているかどうかではなく、組織が何をコントロールしていて、何をサードパーティに依存しているのかということです。
次に、現代の企業において人工知能が実際にどのような姿をしているのかを見ていきましょう。
今日のエンタープライズAIの姿
AIが何を意味するのかを明確に定義するのは、思っている以上に難しいことです。ITの専門家10人に尋ねれば、10通りの異なる答えが返ってくるでしょう。相手によって、それはチャットボット、基盤モデル、機械学習パイプライン、アルゴリズム、インフラストラクチャーを意味し得ます。いずれも正しいのです。
学術分野としてのAIは、1960年代から存在しています。その本質は、知的な振る舞いの側面をシミュレートするコンピューティングです。今日、AIが成熟し、クラウドやDevOpsと交差するにつれて、それは科学分野から産業領域へと進化しつつあります。
AI 運用モデル
セキュリティチームは、自社の組織の中でAIが実際にどのような形で現れているのかを理解しなければなりません。次のセクションでは、こうしたシステムがどのようなものか、どのように構築されるのか、そしてなぜさまざまな形で導入されるのかを整理していきます。
AIバリュースタック
これを考えるうえで有用なのが、McKinseyのような企業が生成AIを論じる際によく用いる、メーカー、シェイパー、テイカーというフレームワークです。
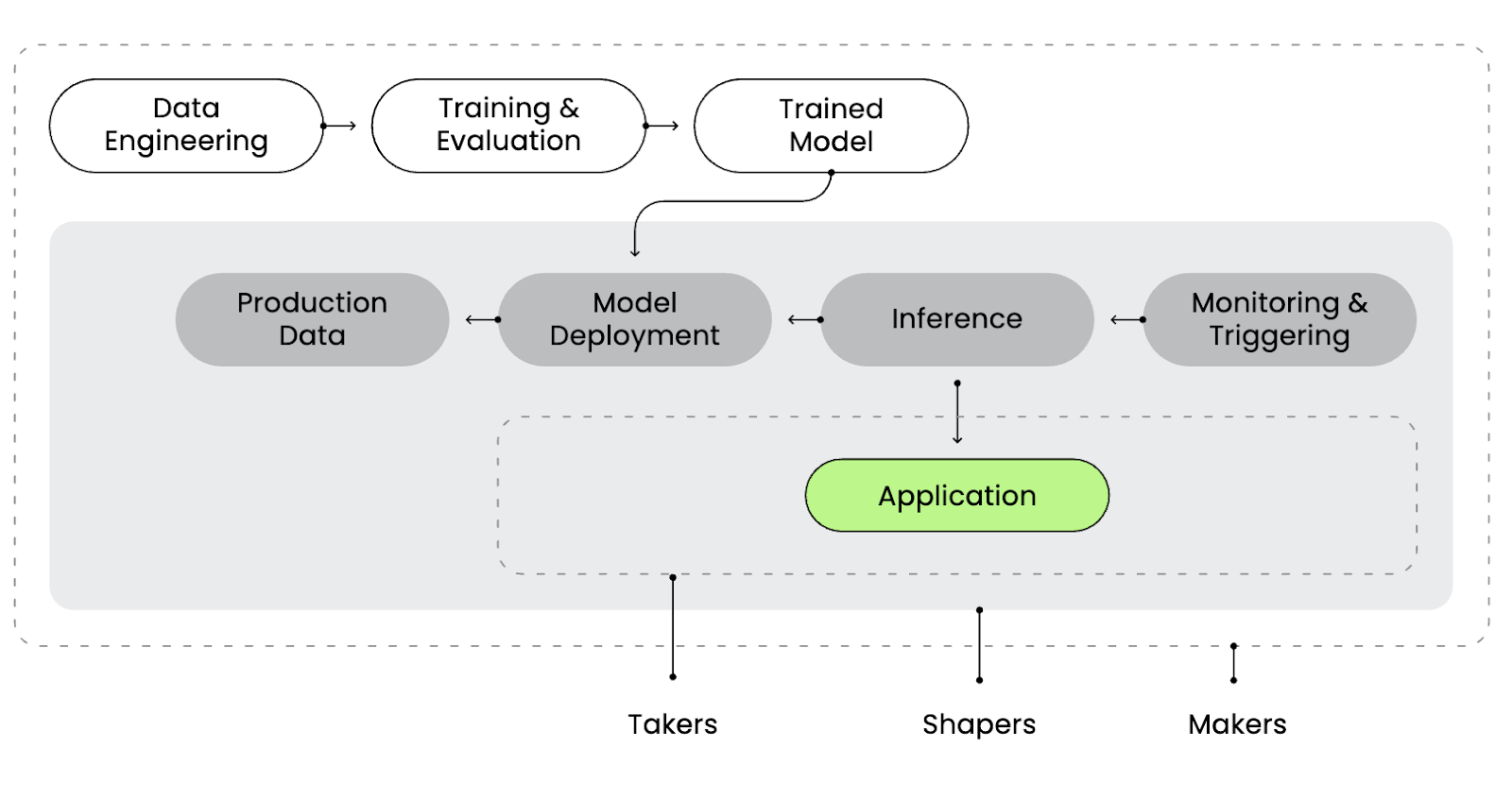
メーカーは比較的少数のグループであり、フロンティアモデルのベンダー、クラウドプロバイダー、スタートアップ、研究機関などが含まれます。これらは、大規模なGPU能力と膨大なデータを用いて基盤モデルを訓練しています。
テイカーには、ChatGPT、Gemini、Copilot などのプラットフォームを通じてAIの機能を直接利用する組織や個人が含まれます。
その両者の間には、幅広いシェイパーのエコシステムがあります。これは、AIシステムの上に製品を構築し、ファインチューニング、検索レイヤー、または独自データの統合を通じてモデルを適応させる企業群です。
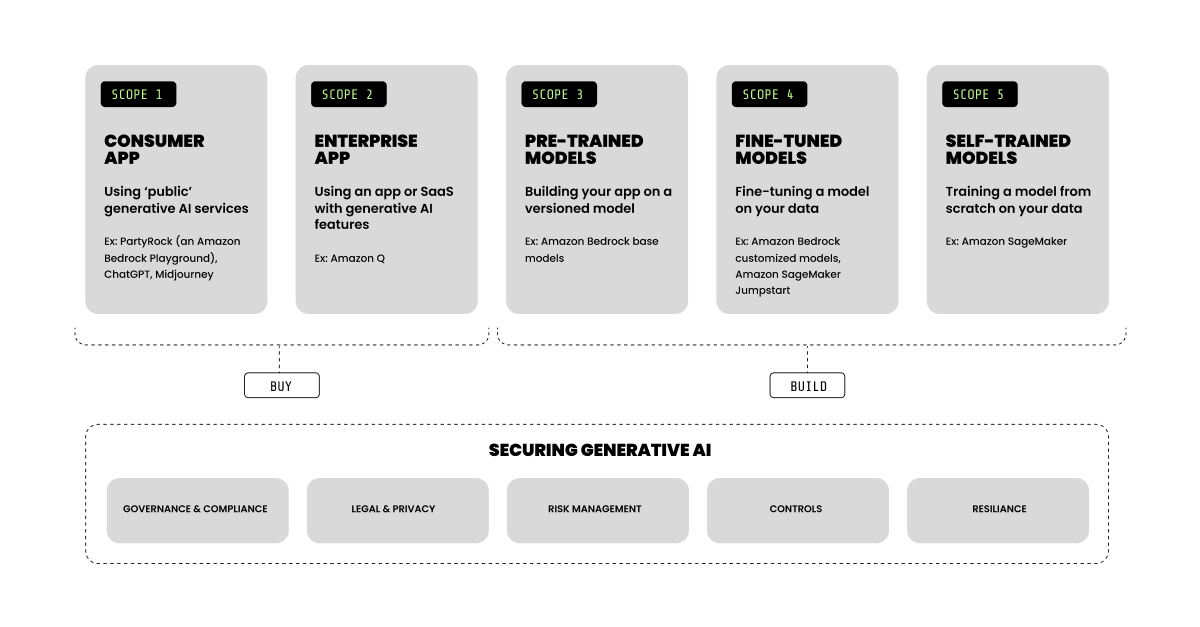
より運用面に即した視点として、Amazon Web Services の AI Security Scoping Matrix は、AIシステムを5つの異なる責任領域に分けています。これは、セキュリティ上の責任を考える際に有用な参考資料です。
アーキテクチャーパズル
先に述べたように、AIは幅広い分野です。以下では、いくつかの基本的な違いとそのリスクプロファイルを見ていきます。これは大まかな概要にすぎません。より詳細な議論については、関連するブログシリーズを参照してください。
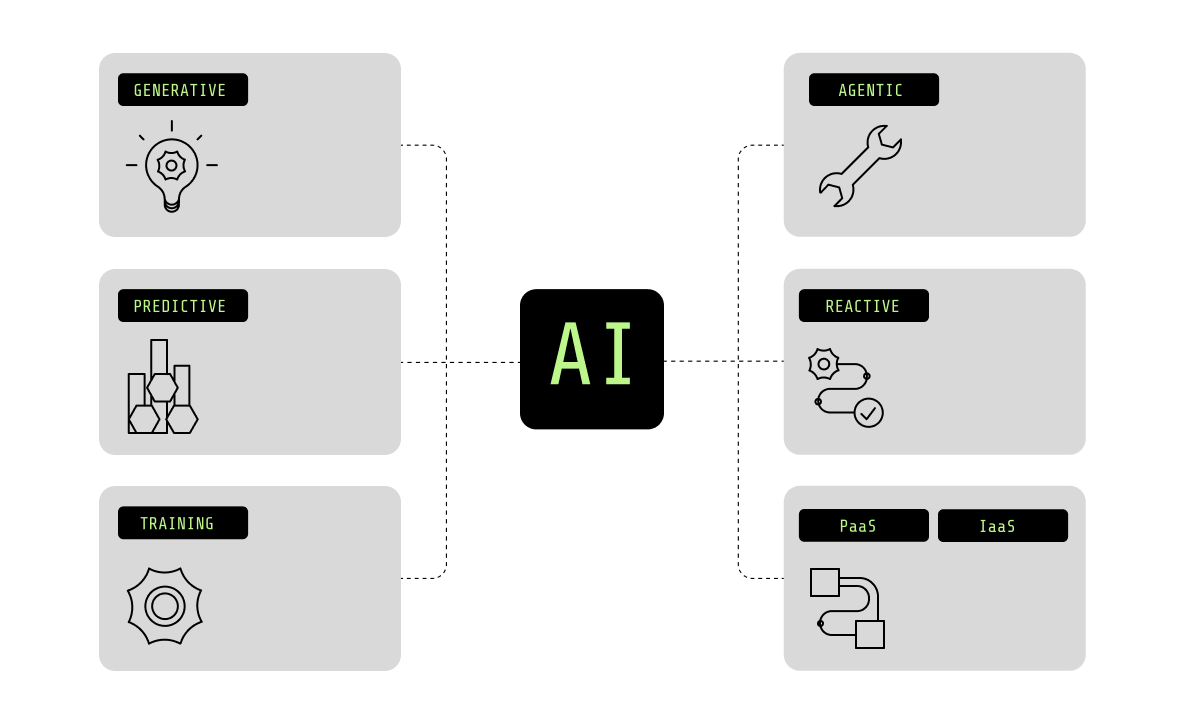
生成型と予測型
生成AIは近年大きな広がりを見せていますが、AIはそれにとどまりません。
生成系システムはオープンエンドな出力を生み出し、通常は対話型であるのに対し、予測系システムはより制約されており、意思決定志向です。生成系システムは、複数のデータソースを組み合わせることが多く、テキスト、コード、画像、応答を生成するコパイロット、エージェント、アシスタントを支えています。予測系システムは、ビジネスロジックやトランザクションフローの中で動作し、不正検知、需要予測、レコメンデーションエンジン、リスクスコアリングといったユースケースを支えます。
この違いは、アーキテクチャー、露出、コントロール戦略を形作ります。
セキュリティの観点から見ると、生成系システムはデータを集約し、ワークフロー全体にわたってユーザーを導く傾向があるため、セキュリティをより利用しやすいものにします。これに対して予測系システムは、プロファイラーとして機能し、パターンを識別し、不審な活動にフラグを立てます。
リアクティブ型とエージェント型
エージェント型システムは、複数のステップにまたがって動作し、より長く持続するセッションを維持し、ツールを呼び出し、目的を達成するためにシステムへアクセスします。一方、リアクティブ型システムは、リクエストを実行して結果を返します。
こうした違いは、セキュリティ上の露出とコントロールを形作ります。
トレーニングと推論
トレーニングパイプラインは、先に定義したメーカーのカテゴリにより近い位置にあります。そこでは、データ、モデルアーティファクト、そして多くの場合、GPUのような専用コンピューティングリソースが、高い権限を持つコントロールプレーン内に集中しています。これらは頻繁にインターネットに面しているわけではありませんが、重要な知的財産を保持していることがよくあります。
推論サービスは、シェイパーが活動する場です。これらのサービスは、モデルをライブトラフィック、API、内部システムに接続します。認証情報、検索レイヤー、リアルタイム実行を扱います。主たるリスクは、集中したモデル資産から、ランタイム時の露出とシステム統合へと移ります。
セキュリティの観点から見ると、トレーニングは資産を保護することに関わります。推論は、露出とランタイムプロセスを制御することに関わります。
IaaS、PaaS、SaaS
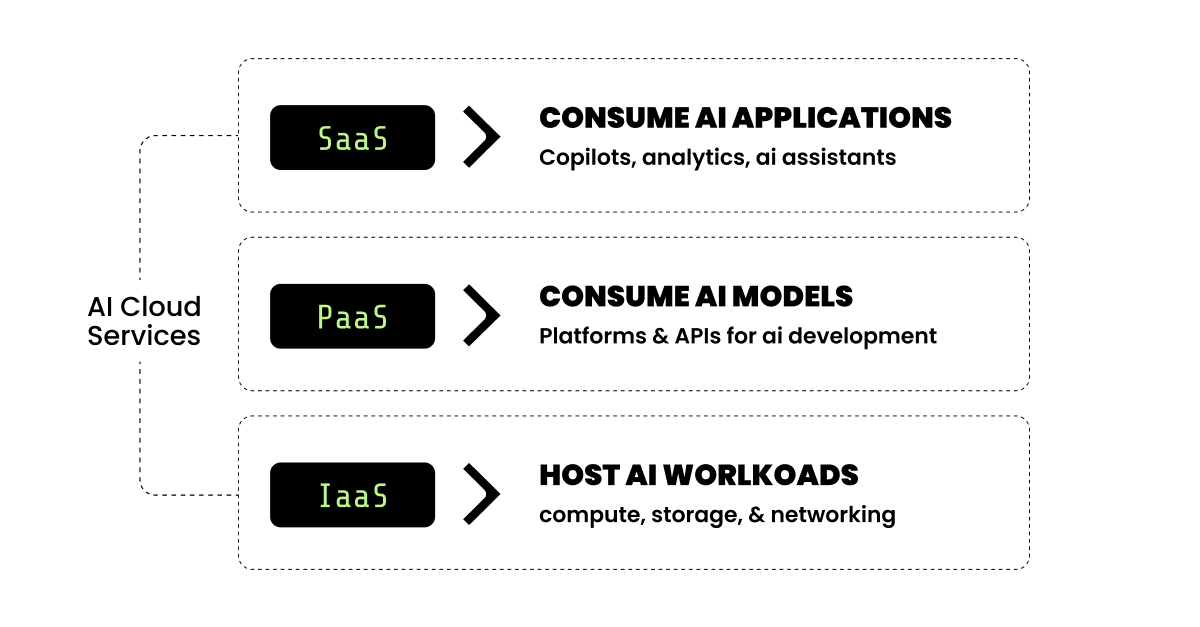
同じ課題でも、まったく異なるアーキテクチャーで解決されることがあります。
ある構成では、GPUクラスターを基盤とするKubernetesベースの環境でモデルを学習またはファインチューニングし、高スループットのネットワークを活用しながら、データの集積場所を考慮して主要なデータセットをオブジェクトストレージに保持します。生成されたモデルはその後、同じクラウドまたは別のクラウドで推論用にデプロイされ、APIを通じて公開されて業務アプリケーションに統合されます。このパターンの詳細な例は、「Securing GPU-accelerated AI workloads in Oracle Kubernetes Engine」で取り上げられています。
別の構成では、AWS Bedrock や GCP Vertex のようなマネージドサービスを使って基盤モデルを採用し、プラットフォームAPIを通じてそれをRAGデータベースに接続します。
同様のユースケースであっても、アーキテクチャーや責任の境界は大きく異なる場合があります。その理由はさまざまで、主権要件から性能や精度の制約に至るまで多岐にわたります。
今日の企業の運営方法
生成AIは、もはや実験的なものではありません。
Turingの「State of AI Adoption 2025」によれば、企業の80%が、生成AIおよびLLMベースのツールを中核的なワークフローに導入または統合しています。McKinseyは、生成AIを日常的に利用している組織の割合を65%としており、これは前年比でおよそ倍増しています。
しかし、その勢いは成熟を意味するものではありません。Information Services Groupは、エンタープライズのユースケースのうち本番環境で全面的に稼働しているのは31%にとどまるとしており、多くの取り組みが依然として移行段階にあることを示しています。
いくつかの指標は、生成系システムと予測系システムを区別しています。フィラデルフィア連邦準備銀行は、調査対象企業の50%が生成系ツールを利用している一方で、従来型AIの導入を報告した企業は23%だったとしています。生成系ワークロードは急速に増加していますが、予測系システムも依然として業務プラットフォーム全体に組み込まれています。
導入パターンはまた、組織がこの技術をどのように利用しているかも示しています。Menlo Venturesによれば、ソリューションの76%は社内で構築されるのではなく購入されています。インフラストラクチャーも同様の傾向をたどっています。BentoMLの調査では、組織の77%が推論ワークロードをパブリッククラウド上で実行しており、30%がオンプレミス環境での導入を報告していて、その多くはハイブリッド構成です。
エージェント型システムは、依然として導入の初期段階にあります。McKinseyによれば、少なくとも1つの機能でそれらを本格展開している組織は23%であり、39%は実験段階にあります。
変化し続ける標的を守る
前のセクションで示したように、AIは多様で断片的であり、その急速に進化するスタックもまた同様です。
セキュリティ担当者にとって、優先すべきは可視性です。見えていないものは守れません。彼らは、自組織が導入しているAIシステムを理解し、必要とされる規模とスピードでそれらを保護しなければなりません。
最近の攻撃や脆弱性が明らかにしていること
AIシステムの実際のリスクと、私たちのコントロールの有効性を理解するためには、近年AIインフラストラクチャーを標的としてきた攻撃を検証する必要があります。
以下の指標は、直接比較できるものではありません。数値の多くはダウンロード件数を反映しています。しかし、これらを総合すると、明確な傾向が見えてきます。AI導入が加速し、インフラストラクチャーの相互接続性が高まるにつれて、攻撃は規模を増しているのです。
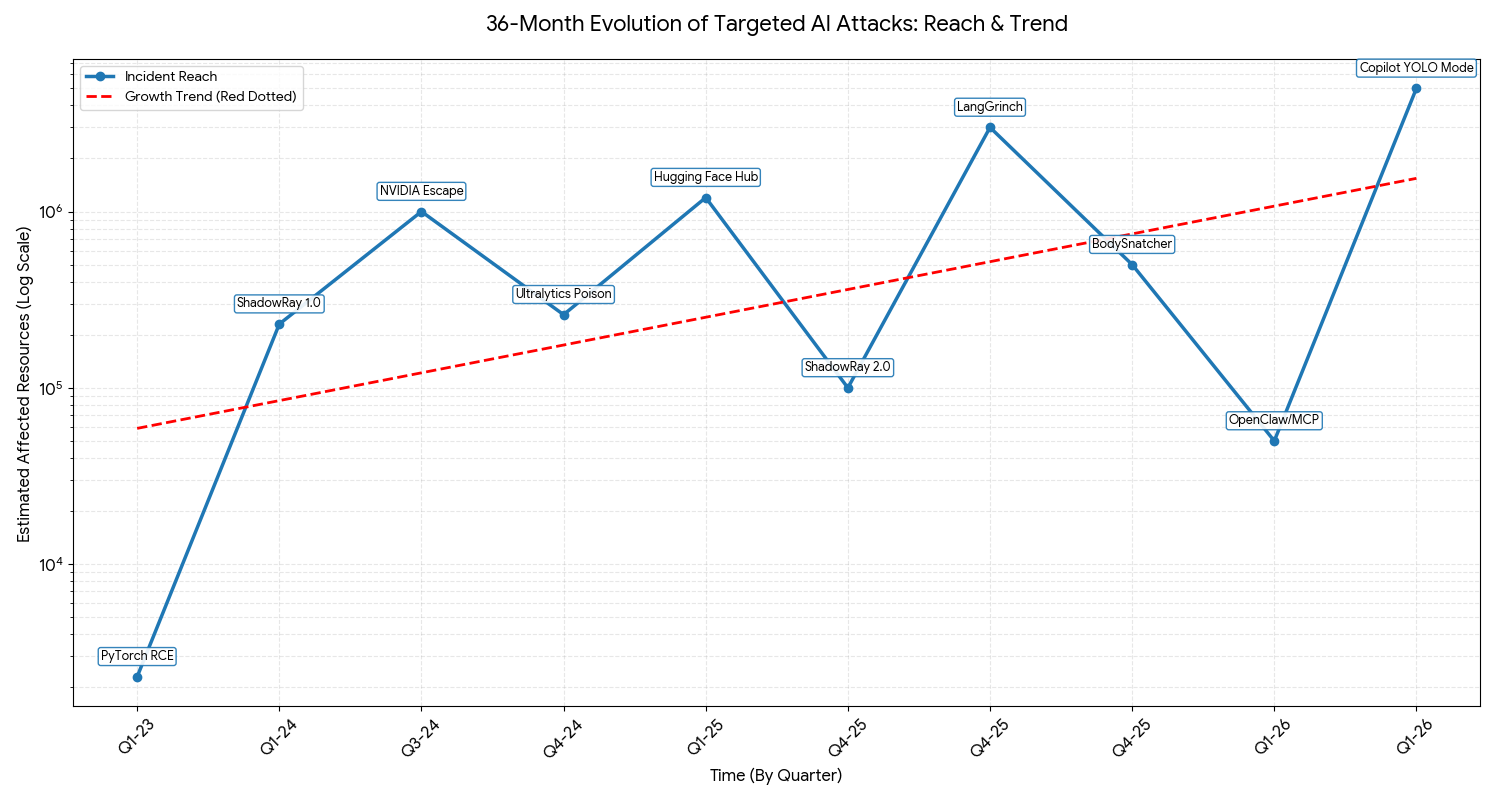
技術的な深度の増大は、しばしばAI駆動のツールを活用する、より能力の高い敵対者の存在を示しています。より広範な影響は、導入のスピードと、露出したインフラストラクチャーの拡大を反映しています。
注目すべきことに、本稿の編集過程において、エージェント関連のセキュリティ問題がいくつか公表されました。その中には、AI生成の指示が内部データの露出につながった最近のMetaのインシデントも含まれており、これはエージェントの能力が急速に拡大し、外部システムと深く統合されていることを反映しています。
問題は理解できましたが、どこで制御すべきかは理解できていません
これらすべてのインシデントにおいて、侵害の経路はプロンプト操作や汚染されたトレーニングデータとは関係ありませんでした。問題だったのはインフラストラクチャーでした。すなわち、アクセス制御、ネットワークの露出、ストレージ設定、改変されたコンポーネント、あるいはランタイム操作です。
現在のAIセキュリティに関する議論の多くは、プロンプト分析や、テキスト入力を通じたレッドチーミングに焦点を当てています。これらの取り組みは重要ですが、問題の一側面にしか対処していません。インフラストラクチャー層は比較的注目されていませんが、実際にはプロンプトレベルのリスクの一部は設計上の欠陥です。
ゼロデイ脆弱性は依然として避けられないリスクであり、予告なく出現する可能性があります。設定ミスは本番環境に紛れ込みます。シャドーAIシステムは正式なガバナンスの外で出現し、監視されないままになります。善意で設計されたアーキテクチャーでさえ、時間の経過とともに変質していきます。
だからこそ、AIインフラストラクチャーの保護は、セキュリティの議論において独自のカテゴリに値するのです。
神経内科医の視点を採る
心理学者が行動を研究する一方で、神経内科医がその行動を生み出すシステムを研究するのと同じように、サイバーセキュリティツールも異なるレイヤーで機能します。
クラウドワークロード保護プラットフォーム(CWPP)は、ワークロードそのものの内部構成、アクセス、リアルタイムのシグナルを分析します。
これに対して、Webアプリケーションファイアウォール(WAF)や、より最近ではLLM保護プラットフォームのようなツールは、主に入力と出力を分析します。
このたとえで言えば:
- 心理学者 → 入力と出力を分析します
- 神経内科医 → 内部構成とシグナルを分析
会話を保護していても、それを生み出しているインフラストラクチャーを無視しているのなら、私たちは原因を見落としたまま症状だけを扱っていることになります。
視点から実践へ
ここにこそ変化があります。意味のあるAIリスクは、必ずしもプロンプトに起因するのではなく、インフラストラクチャー、サプライチェーン、実行環境に起因します。
そのリスクに対処するには、表層的なコントロールを超えて、AIシステムが実際にどのように構築され、運用されているのかに焦点を当てる必要があります。つまり、それらがどこで稼働しているのか、どのように設定されているのか、そして本番環境でどのように振る舞うのかを理解することを意味します。
ここで、そのアプローチは具体的なものになります。
完全な保護アプローチ
先に説明した神経内科医のワークフローは、4つの実践的な管理領域に分かれています。
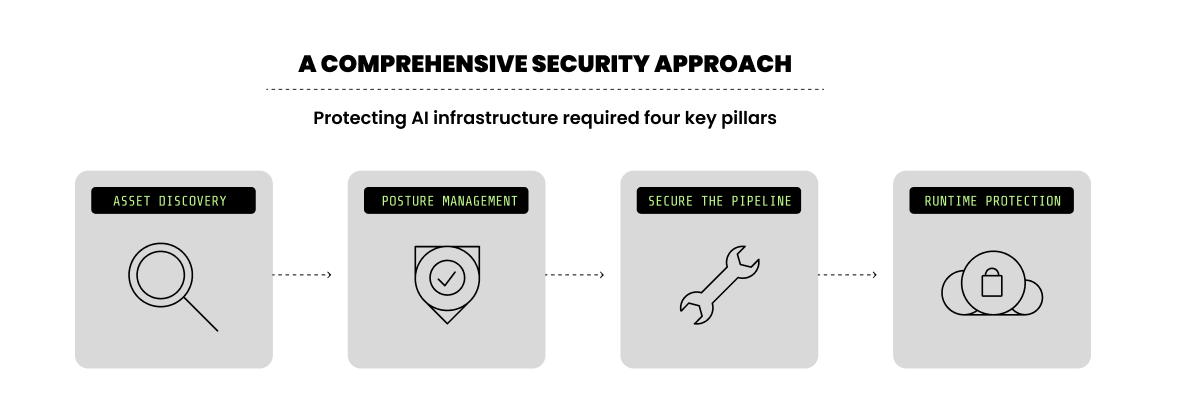
ディスカバリーには、SaaS、PaaS、IaaSの各レイヤーにまたがるAI固有の資産を含めなければなりません。
ポスチャー管理では、設定ミス、公開されたエンドポイント、過剰な権限、脆弱な依存関係を継続的に評価しなければなりません。個別の検出結果よりも、攻撃経路のほうが重要です。
シフトレフトのコントロールは極めて重要です。脆弱性やリスクの高い設定は、デプロイ前にイメージ、パイプライン、インフラストラクチャー定義の段階で特定されるべきです。
そして最後に、ランタイム保護は不可欠です。悪用はコンテナやクラウドサービスの内部で発生します。ランタイムの振る舞い、権限の使用、異常なアクティビティを監視することが、設定ミスが侵害へと発展するのを防ぐのです。
AI-SPMやAIBOMだけでは十分ではありません。AIインフラストラクチャーには、高価値のクラウドワークロードに適用しているのと同じ深さのコントロール、あるいは、関与するデータ、計算資源、権限の集中度や、AI関連の侵害コストの上昇を考えれば、それ以上の深さのコントロールが必要です。また、それらのコントロールは、AIスタック全体にわたる固有の技術や高い断片化に対処するために、専門化されていなければなりません。
AI インフラストラクチャー セキュリティーの運用
Sysdigでは、このアプローチをインフラストラクチャーセキュリティに適用し、MLやLLMシステムを含むAIサービスやソフトウェアにまで、クラウドネイティブなコントロールを拡張しています。
このフレームワークには、以下が含まれます。
- AIBOM 関連するサービス、ワークロード、および信頼できる境界を浮き彫りにします。これはシャドウ AI の盲点を取り除くために不可欠です。
- リスク管理 これにより、実際の攻撃経路、使用中の脆弱性、危険な構成ミスが優先されます。
- シフトレフトセキュリティ これにより、脆弱なイメージや危険な構成が本番環境に移行するのを防ぐことができます。
- ランタイム境界の保護 コンテナとクラウドサービス内の実行動作と権限の使用状況を監視します。
ますます、AIはAIを保護するうえでも役立つようになっています。Sysdig Sage™ のようなAIアナリストを活用したり、セキュリティインサイトをエンタープライズ向けLLMのワークフローに直接統合したりすることで、チームはより迅速に調査を進め、運用上の摩擦を軽減できます。
LLM アプリケーションで Sysdig を使用する
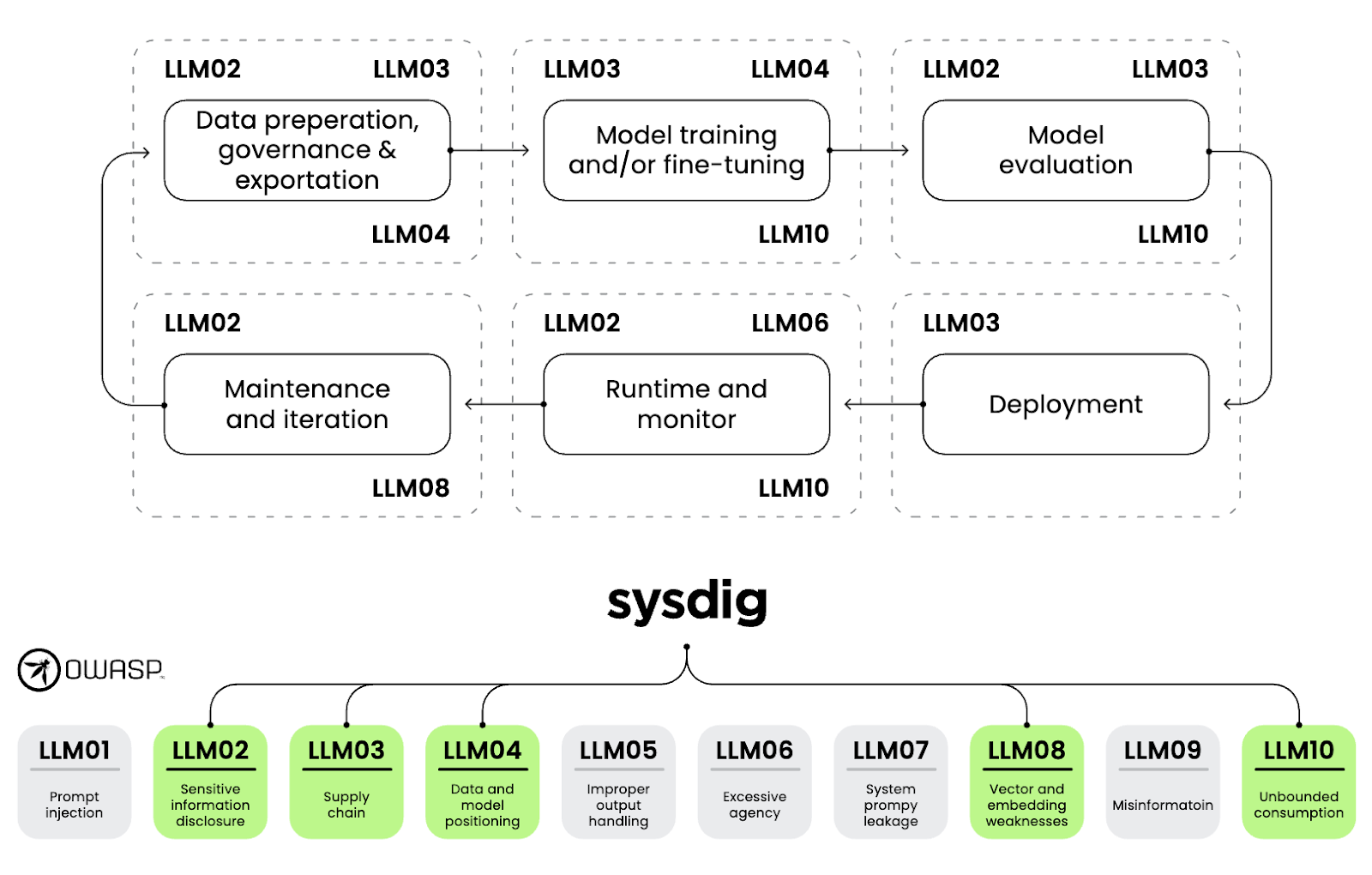
大規模言語モデル向けOWASP Top 10は、これらの考え方を実際のセキュリティシナリオに結び付けるうえで有用な枠組みを提供します。このリストは、トレーニングと推論の両方におけるリスクを対象としており、LLMシステムを保護する際に実務担当者が直面する課題を反映しています。次の図は、これらのリスクを関連するSysdig CNAPPの機能に対応付けたものです。
まとめ
エンタープライズAIはクラウドインフラストラクチャー上で稼働します。そこでは、データ、計算資源、権限が、露出と影響の両方を増大させる形で集中します。
入力と出力を保護するだけでは十分ではありません。システム自体を保護する必要があります。詳しくは、SysdigのAIワークロード保護機能についてご覧いただき、AI攻撃に関する詳細情報についてはSysdigの脅威リサーチレポートをご参照ください。