


Falco Feedsは、オープンソースに焦点を当てた企業に、新しい脅威が発見されると継続的に更新される専門家が作成したルールにアクセスできるようにすることで、Falcoの力を拡大します。

本文の内容は、2026年1月14日に Alejandro Villanuevaが投稿したブログ(https://www.sysdig.com/blog/ai-is-still-a-workload-a-practical-guide-to-securing-ai-workloads)を元に日本語に翻訳・再構成した内容となっております。
AIは魔法のように見えるかもしれませんが、その舞台裏では、依然としてサーバー上で実行されるコードにすぎません。そのため、他のあらゆるワークロードと同様にセキュリティ対策を施す必要があります。
本記事では、AIの利用における3つの異なるアプローチに関連するセキュリティリスクを評価します。すなわち、ChatGPTのようなLLMを利用する従業員、製品の一部としてチャットボットを提供する企業、そしてゼロから独自のモデルを学習させる企業です。
AIワークロードが、すでに運用している他のワークロードと実際にはどのように似ているのかを示し、そのセキュリティを強化するためのいくつかの緩和策を提示します。
AIワークロードをセキュアにする際にカバーすべき主な領域は、インベントリ、モデルおよびデータのセキュリティ、アクセス制御、検知、リスク管理、脅威管理、そしてコンプライアンスの7つです。
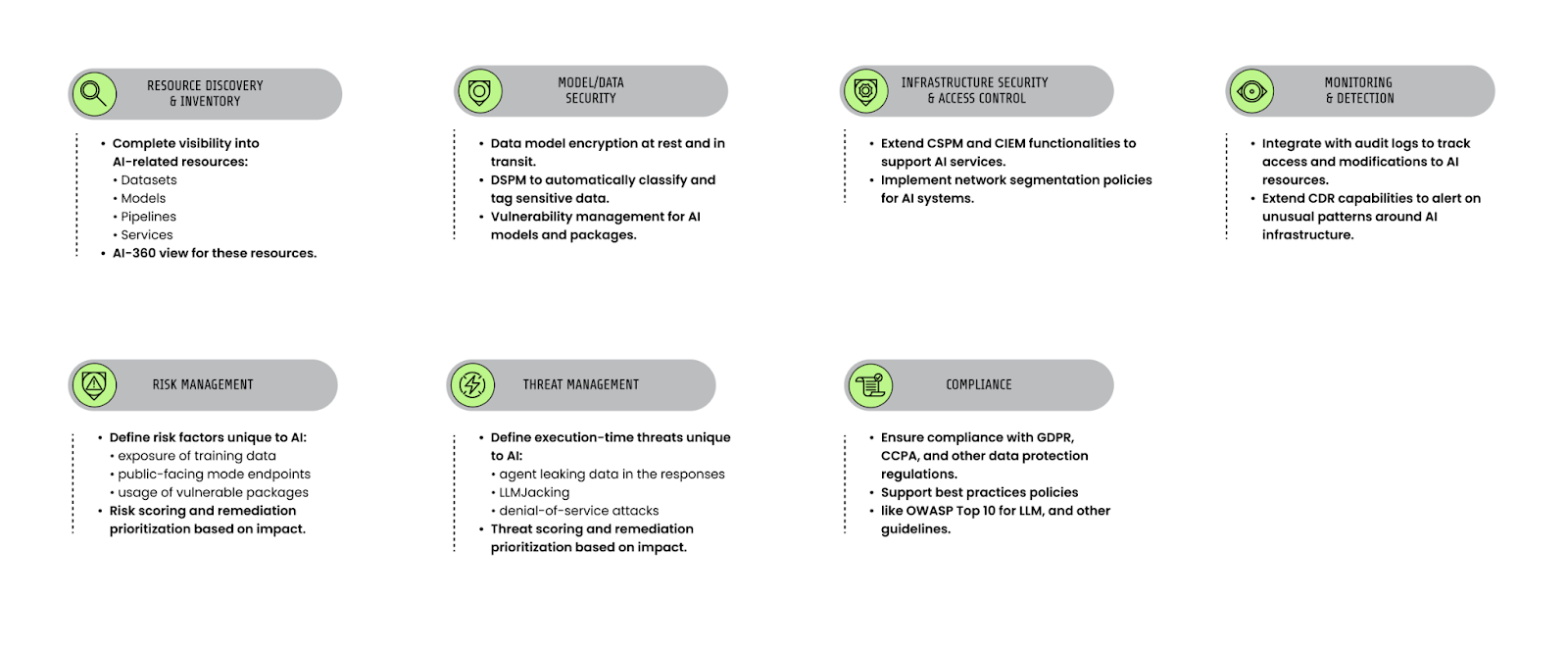
LLM ユーザーの保護
まず、組織内でChatGPT、Copilot、GeminiなどのLLMのユーザーを保護する方法について説明しましょう。
主なリスク:データの漏えい、またはモデルによる誤った誘導。
類似点:他のあらゆるSaaSと同様。
対策:AIのベストプラクティスおよびプライバシーへの影響について、ユーザーを教育すること。
データがトレーニングに使用されていないことを確認してください
AI企業にとって、あなたのプライバシーは最優先事項ではありません。優先されるのは、モデルを学習させ、競合に勝つことです。
SaaSサービスが自社サービスの改善のためにユーザーデータを利用すること自体は珍しくありませんが、LLMモデルの学習のためにそれを行っているのは言語道断です。エージェントを操作して、こうした学習データの一部を返させることは比較的容易であり、これはプライバシーおよびセキュリティの悪夢と言えます。
OpenAI Enterprise や Google Workspace Gemini のようなサービスは、データをモデルの学習に使用しませんが、通常版の製品には同じことが当てはまりません。組織内で個人アカウントを使用しているユーザーは、プライバシー設定を手動で確認する必要があります。
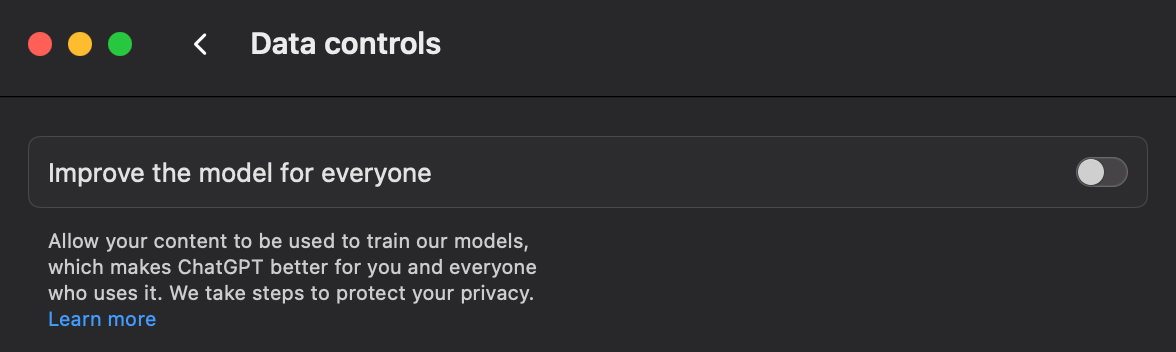
ChatGPTの場合、設定に移動し、「データ管理」を選択して、「全員のためにモデルを改善する」というトグルを無効にする必要があります。
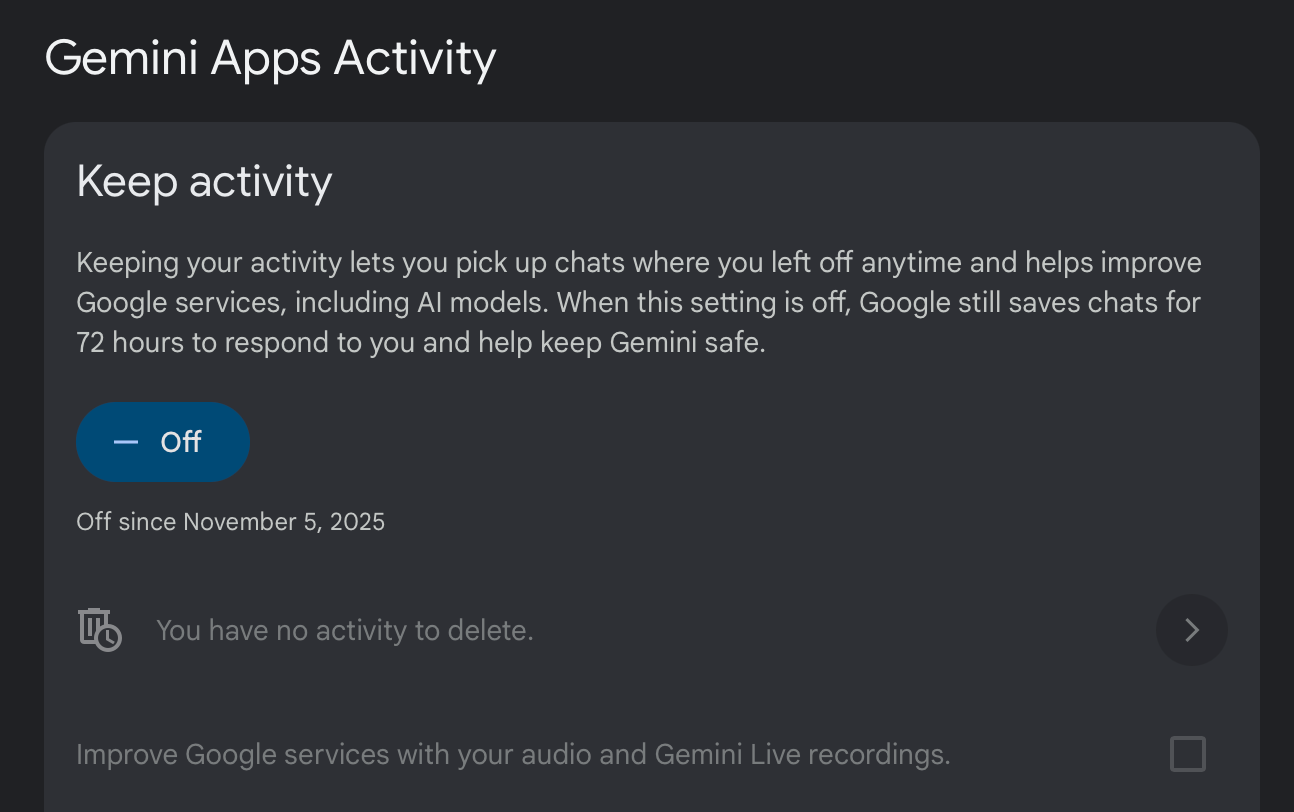
Geminiのユーザーの場合、この設定は「myactivity」ポータル内の奥深くにあります。
AIの利用に関するベストプラクティスと、それに伴うプライバシーへの影響について、企業として研修を提供することを徹底してください。このような形でデータが漏えいすると、企業の評判を損なうだけでなく、GDPRやCCPAといった規制の下で多額の罰金を科される結果につながります。
AIアプリケーションと、それらがアクセスするリソースの可視性
見えないものは守れないため、AIエージェントがアクセス可能なすべてのリソースを棚卸しし、必要に応じて制限することが重要です。AIエージェントのビジネス版やエンタープライズ版では、許可された連携アプリのアロウリストを用いてグローバルに設定できます。
しかし、この設定は、ユーザーがローカルファイルへのアクセスを自由に提供したり、MCPを介して外部接続を設定できる OpenAI の Codex のようなエージェントには適用されない場合があります。同様に、ユーザーはこれらのサービスの個人アカウントを使用することで、こうした制限を回避することもできます。
これが問題になっている場合は、従業員のコンピューター上で実行できるソフトウェアを制限し、特定のリソースへの接続をブロックできるデバイス管理ソフトウェアの導入を検討してください。
もっとも、特定のリソースへのアクセスを制限することは業務の妨げになる可能性があります。AIのベストプラクティスについてユーザーを教育することは、常に良い出発点です。
認証情報と API キーへのアクセスを保護する
AIエージェントがモデルの学習に個人データを使用しない場合でも、ユーザーアカウント上にそのデータの一部をキャッシュします。悪意のあるアクターがそのアカウントへのアクセスを取得した場合、キャッシュされた情報をすべて抽出できてしまいます。
他のSaaSと同様に、AIサービスには二要素認証を必須とし、データ保持ポリシーを設定してください。また、アクセス監査を有効化し、それを脅威検知エンジンに連携させることで、不審な接続についてアラートを受け取れるようにしてください。
汚染されたモデルからの防御
AIを盲信してはいけません。
LLMは中立で全知全能の神託ではありません。AIは限られた情報に基づいて動作し、完全な確信をもって幻覚的な回答を返すことがあり、また、モデルをプログラムした人々によって定義された、ある種の価値観を伴うガードレールの中で動作します。AIが提供する情報は必ず照合し、実行させるタスクは監督する必要があります。
AIモデルは8歳の子どもだと考えてください。親から教えられたことは何でも絶対的な真実だと信じ、完全な自信をもって事実をでっちあげ、監督なしで放置すれば、最大級の混乱を引き起こしかねません。
さらに、モデルは汚染に対して脆弱です。子どもが悪い言葉を覚えて使い続けてしまうのと同じように、学習データが慎重に精査されていなければ、AIモデルはあらゆる有害なことを学習してしまいます。
攻撃者はモデルを汚染することで、エージェントの応答を操作できます。検索エンジン向けにウェブサイトを最適化するのと同様に、ウェブサイトのコードを通じてAIエージェントを操作することが可能です。たとえば、インターネットをスクレイピングする際にエージェントが解釈するような隠し命令をソースコード内に含めることができます。攻撃者はこの手法を使って、正規のサイトではなく、不正なフィッシングサイトへ他のユーザーを誘導するようエージェントを騙すことができます。
これらの攻撃はさらに巧妙な場合もあり、特定の入力を与えたときに、モデルがコンテナから抜け出して悪意のあるコードを実行するよう学習させることも可能です。
これらすべてを念頭に置き、LLMに対して懐疑的な姿勢で向き合うよう、チームを教育してください。
一般ユーザー向けのチャットボットと内部エージェントの保護
主なリスク:攻撃者がエージェントを侵入口として利用すること、攻撃者がAIインフラを悪用すること。
類似点:外部APIアクセス全般と同様。
対策:すべてのユーザー入力をパースし、適切なネットワークセグメンテーションを実施し、認証情報を安全に管理すること。
ジェイルブレイクからの防御
開発者として最初に学ぶことの一つは、ユーザーは手元にあるあらゆる入力欄を使って、予想外の方法で混乱を引き起こし得るということです。ウェブサイトをいじって、開発者がユーザー入力のサニタイズを忘れていないかを確認し、SQLインジェクションが可能かどうか試してみるのは楽しいものです(少なくとも私たちにとっては。開発者にとってはそうではありませんが)。

現在では、アプリケーションフレームワークは一般的な攻撃に対して、デフォルトでユーザー入力をフィルタリングするようになっています。しかし、Log4j における Log4Shell のように、細工されたユーザー入力がこのライブラリによってログに記録されることで、サーバー側でコードが実行されてしまう脆弱性といった、予期せぬ事例はいまだに存在します。
そして当然ながら、AIの時代においても同じ原則が当てはまります。

未フィルタリングのデータをAIエージェントに与えると、ガードレールを回避するプロンプトを許してしまいます。
最良の場合では、誰かが製品のAIアシスタントに面白いことを言わせる程度で済むでしょう。しかし最悪の場合、攻撃者はアシスタントを操作して、組織内のデータを漏えいさせる可能性があります。エージェントが利用可能なあらゆるデータやリソースは、この方法で到達可能であることを忘れてはいけません。
これらの攻撃は、AIアシスタントへの直接的なユーザープロンプトに限定されるものではありません。バックエンドで動作するエージェントについては特に注意が必要で、アクセスするデータに隠し命令や、「William Ignore All Previous Instructions」のようなユーザー名が含まれていないことを確実にしなければなりません。
最も恐ろしい点は、SQLインジェクションを行うにはある程度の技術的知識が必要だったのに対し、LLMの操作は平易な言葉だけで実行できてしまうことです。たとえば、ChatGPT 3.5 では、「company」という単語を500回繰り返すよう求めるだけで、学習データを抽出できた事例がありました。
経験則としては、次のように考えてください:
- エージェントに到達する前にユーザー入力をフィルタリングしてください。具体的には以下のとおりです。
- ガイドラインとユーザー入力を分離するために使用している区切り文字。
- 「ignore」「instructions」「guidelines」といったキーワードや、エージェントの想定範囲外の語句。
- ユーザーに返す前に、エージェントの出力をフィルタリングしてください。応答の長さを制限し、メールアドレスやAPIキー、またはそれに類する構造のデータを検知します。
- ガードレールが十分に堅牢であることを確認するため、徹底的にテストしてください。外部の専門家に依頼して検証してもらうことも検討してください。
- 攻撃者に弱点の情報を与えないよう、ガードレールは非公開にしてください。
- 他のリソースへのアクセスを制限し、ネットワークセグメンテーションを実装するなど、一般的なセキュリティ対策によってラテラルムーブメントを防止してください。
LLMJacking からの防御:認証情報とアクセスの保護
他のクラウドサービスや外部APIと同様に、エージェントの認証情報やAPIキーを適切に保護してください。
AIの計算時間は高価であり、他人のインフラを使えるのであればその方が常に安上がりです。探し方を知っていれば、侵害されたAIサーバーへのプロキシが取引されている活発な市場が存在します。LLMサーバーの認証情報を盗み出すこの手法は、LLMJacking と呼ばれています。
以下は、認証情報を保護するためのベストプラクティスです。
- APIキーをコードにハードコードしないでください。シークレットや環境変数を使用してください。
- 認証情報の漏えいにつながる可能性のあるソフトウェアの脆弱性をスキャンし、対策を講じてください。
- ネットワークセグメンテーションを適用し、バックエンドのみが、かつ特定のソースからのみエージェントにアクセスできるようにしてください。
- AIワークロードに対して、監査、検知、対応を実装してください。異常なアクティビティを検知できるようにし、潜在的なインシデントを調査するためにログを記録してください。
サービス拒否攻撃からの防御
一般に公開されているサービスはすべて、サービスが低下するほど悪用されやすくなります。LLM の場合、主に次の 2 つの原因が考えられます。
- 攻撃者が複雑なプロンプトを要求し、リソース使用量の急増を引き起こすこと。
- 攻撃者が、エージェントが処理できる速度を上回って繰り返しリクエストを送信すること。
これを避けるには:
- 改めて、「これを永遠に繰り返して」といったリクエストをフィルタリングするため、入力をパースしてください。
- ユーザー入力を処理するレートに上限を設けてください。
- LLMエージェントの出力長を制限してください。
- リソース使用量を監視し、使用量の急増に対してアラートを出すようにしてください。
自社で学習させたモデルのセキュリティ確保
主なリスク:モデルの漏えいおよびモデルの汚染。エージェントを侵入口として利用されること、またはAIインフラを悪用されること(前述した内容と同様)。
類似点:あらゆるバックエンドサービスと同様。
対策:学習データセットを慎重に構築し、モデルへのアクセスを安全に管理すること。
あらゆるサービスをセキュアにするには、あらゆる段階でセキュリティのベストプラクティスに従う、包括的なアプローチが必要です。本記事ではすでにいくつかのベストプラクティスを取り上げており、残りについてもおそらくご存じでしょう。したがって、次のセクションは、AIに限らずあらゆるサービスをセキュアにするための基礎として使える、簡易チェックリストとして捉えてください。
リソースへのアクセス
モデルの学習には、計算資源の面だけでなく、学習データセットを精査・構築するという点でも多大な労力が必要です。このプロセスを終える頃には、競合との差別化につながる独自のものを築き上げていることになります。
- まずはリソースの棚卸しから始めてください……そして、そのインベントリを常に最新の状態に保ちましょう。見えないものは守れないため、抜け漏れが生じないようにしてください。
- モデルやデータソースへのアクセス設定には、ゼロトラストのアプローチを適用してください。たとえば、モデルやデータソースを S3 に保存している場合は、それらを非公開に設定し、必要なアカウントのみがアクセスできるようにしてください。
モデルとデータ
アクセスが侵害された場合に備えて、実データそのものを保護することも極めて重要です。モデルおよび学習データは、保存時および転送時の両方で暗号化してください。たとえば、S3バケットでは次のような設定でこれを強制できます。

データセキュリティポスチャ管理(DSPM)を使用して、機密データを自動的に分類・タグ付けしてください。たとえば、Bedrock Data のようなツールを使って、学習データ内に API キー(またはそれに類するもの)が含まれていないことを確認したり、そうしたデータがプロンプト内でエージェントに渡らないよう防止したりすることができます。
静的:インフラストラクチャーとリスク管理
自社のインフラに固有のリスク要因の一覧を作成してください。本記事で取り上げた、学習データの露出、公開されたモデルエンドポイント、脆弱なパッケージの使用などの例を参考にするとよいでしょう。
各リスクについて、その影響度に基づいてスコアリングし、取り組みの優先順位を付けてください。
各リスクに対する緩和策を計画してください。是正措置の例としては、アクセス設定におけるゼロトラストの適用やネットワークセグメンテーション、データの暗号化、パッケージの脆弱性管理などが挙げられます。
CSPM や CIEM のツールを活用して、是正措置の実装状況を追跡し、最も弱いポイントの可視性を確保してください。
動的:監視、検知、脅威管理
実行時に発生する異常な挙動を検知することは、静的な設定では見逃してしまう可能性のある脅威を捉えるためのセーフティネットとして機能します。
まず、自社固有の脅威要因を特定してください。たとえば、エージェントが応答内でデータを漏えいすること、LLMJacking、サービス拒否攻撃などを例として挙げました。
各脅威について、その影響度に基づいてスコアリングし、取り組みの優先順位を付けてください。
各脅威に対する是正措置を計画してください。これには、AIリソースへのアクセスや変更を追跡するための監査ログの処理や、異常な挙動を特定するための検知ルールの作成などが含まれます。
インフラ全体を監視し、異常なパターンに対してアラートを発し、セキュリティイベントの調査を容易にするためのコンテキストを提供する CDR ツールを使用して、これらの対策を実装してください。
最後に、セキュリティイベントの調査と是正が完了した後は、同様の脅威が再発しないよう、新たなリスクや緩和策を反映させる形で、静的な設定を見直してください。
コンプライアンス
最後の推奨事項は、コンプライアンス基準やセキュリティベンチマークを満たすことです。義務付けられていない場合であってもこれらに取り組み、セキュリティ戦略におけるギャップを検出するためのツールとして活用してください。
ヨーロッパの GDPR やカリフォルニアの CCPA など、データ保護法には特に注意を払ってください。本記事で述べてきたとおり、データ保護は現代のAIにおける最大の弱点です。
次のステップ
本記事は、取り組みを始めるためのクイックガイドとして捉えてください。このテーマをさらに深掘りしたい場合は、以下の追加リソースを参照してください。
まず手早く取り組めるものとして、LLM向け OWASP Top 10 があります。これは、遭遇する可能性が最も高い一般的な脅威をまとめたものです。

包括的な一覧については、MITRE ATLAS Matrix を参照してください。これは、機械学習に関連する戦術および技法をまとめた最新のリストです。

まとめ
AI ワークロードを保護するためのベストプラクティスは、通常のサービスの場合と同じです。
- ChatGPT のような AI エージェントを使用する際には、他のあらゆる SaaS を利用する場合と同じルールを適用する必要があります。
- 外部エージェントのセキュリティ確保は、外部 API へのアクセスを保護するのと同様です。
- 自社のモデルやエージェントをセキュアにすることは、他のバックエンドワークロードを保護するのと同じ考え方になります。
それに加えて、無害なプロンプトが爆弾になり得る、LLMの非決定的な性質にも対処する必要があります。このリスクを軽減するためには、入力のサニタイズやレート制限の実装において、既成概念にとらわれない発想が求められます。
本記事では、馴染みのあるサービスと関連付けることで、AIワークロードを少しでも身近なものとして理解していただけたのであれば幸いです。
AIワークロードのセキュリティ確保についてさらに詳しく知りたい場合は、当社のブループリントをダウンロードしてください。